返回首页
返回首页

回放:面向复杂图计算应用的新型高能效体系结构 | CNCC论坛分享
2022年12月9日CNCC2022论坛“面向复杂图计算应用的新型高能效体系结构”在线上召开。点击文末左下角“阅读原文”或扫码(仅对CNCC注册参会者开放),可观看论坛视频回放。

扫码观看CNCC技术论坛回放

本次论坛由CCF分布式计算与系统专委会主任、华中科技大学廖小飞教授和华中科技大学张宇副教主持,论坛邀请著名专家学者、企业研究员等嘉宾出席,围绕“面向复杂图计算应用的新型高能效体系结构”主题进行演讲,讨论新型图计算模型和新型高能效图计算体系结构设计,以高效支撑不断涌现的复杂图计算需求,助力图计算体系结构发展和生态成熟。
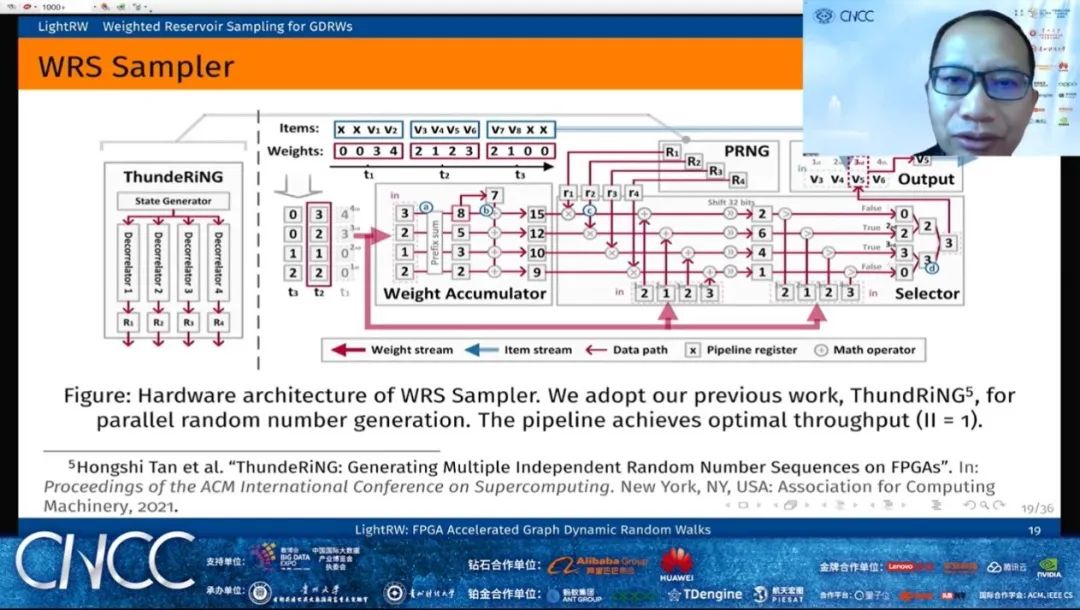
新加坡国立大学计算机学院科研副院长、教授何丙胜,报告的题目是《异构体系结构上的图随机游走加速技术》。何丙胜教授将首先回顾异构体系结构上的图随机游走相关工作,随后介绍了相关研究成果,并演示硬件和软件协同设计对高性能图随机游走系统和应用的显著性能影响。最后,何丙胜教授介绍了图随机游走系统和应用开发中的挑战和机遇。
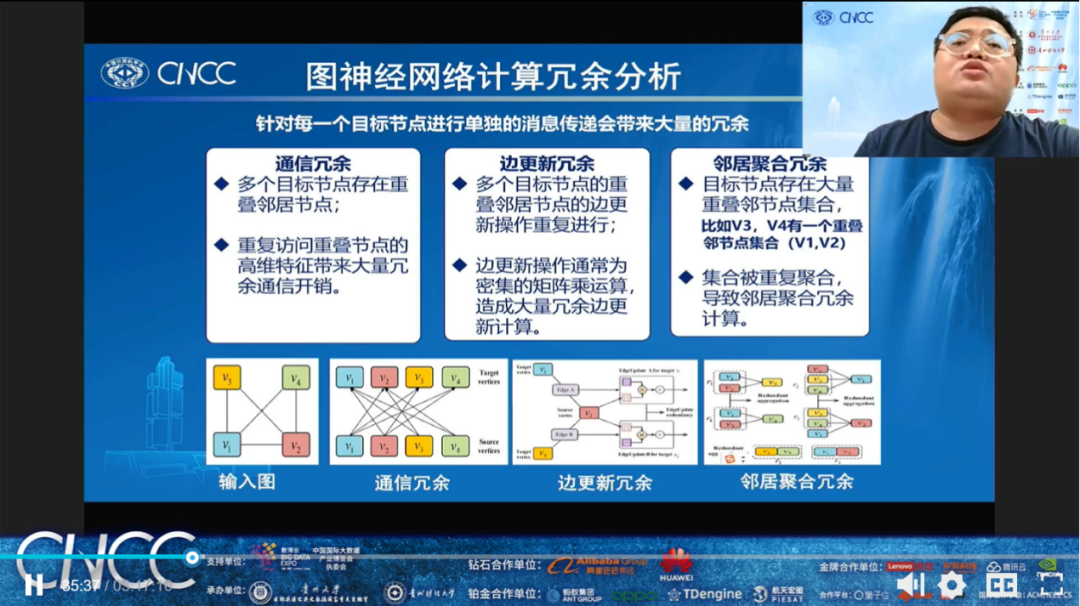
新加坡科技研究院研究科学家陈岑,报告的题目是《面向图神经网络的高效能算法与体系结构协同设计》。陈岑老师提到典型的图神经网络模型大都采用邻域消息传播机制,通过聚合邻居节点的特征来更新目标节点的特征。通过分析,陈岑老师发现邻域消息传播机制的简单实现会导致大量的冗余计算和冗余通信开销。随后,陈岑老师介绍他们的研究工作通过算法与体系结构的协同设计来去除计算过程中的冗余,以此来加速图神经网络。与目前的图神经网络加速器相比,陈岑老师团队提出的图神经网络加速器在不损失网络精度的情况下带来了可观的加速比并极大的降低了能耗。
清华大学交叉信息研究院高鸣宇教授报告的题目是《复杂图计算算法的硬件优化:领域专用加速和近存计算架构》。高鸣宇教授提到,在人工智能和大数据时代,图计算算法逐渐由传统基于边的简单信息传递,演化至图挖掘、图神经网络等复杂应用,但随之而来的系统算力需求也大大提升。随后,高鸣宇教授介绍在面向复杂图计算应用的硬件架构方面的近期工作。一方面,为提高数据处理的性能,高鸣宇教授针对不同图计算算法提出了领域专用硬件架构,包括利用多层次细粒度并行的图挖掘加速,和自适应稀疏度的稀疏矩阵乘法加速。另一方面,为提高数据访问的效率,高鸣宇教授采用近存计算的思想,构建基于3D内存技术的可扩展架构,优化数据划分、数据通信、负载均衡等系统瓶颈,以支持以图计算为代表的复杂且不规则的应用。
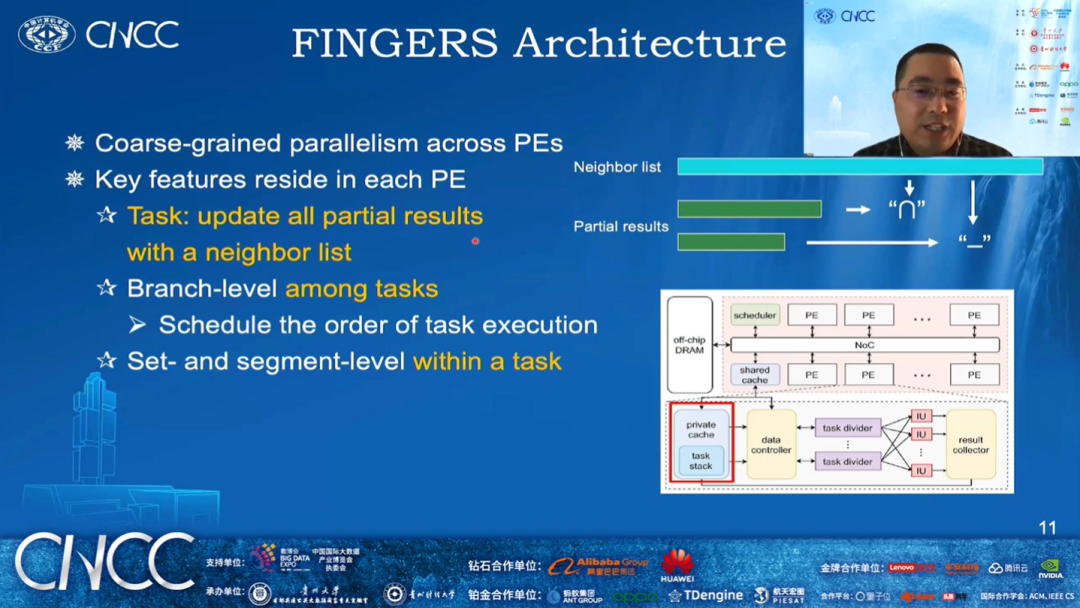
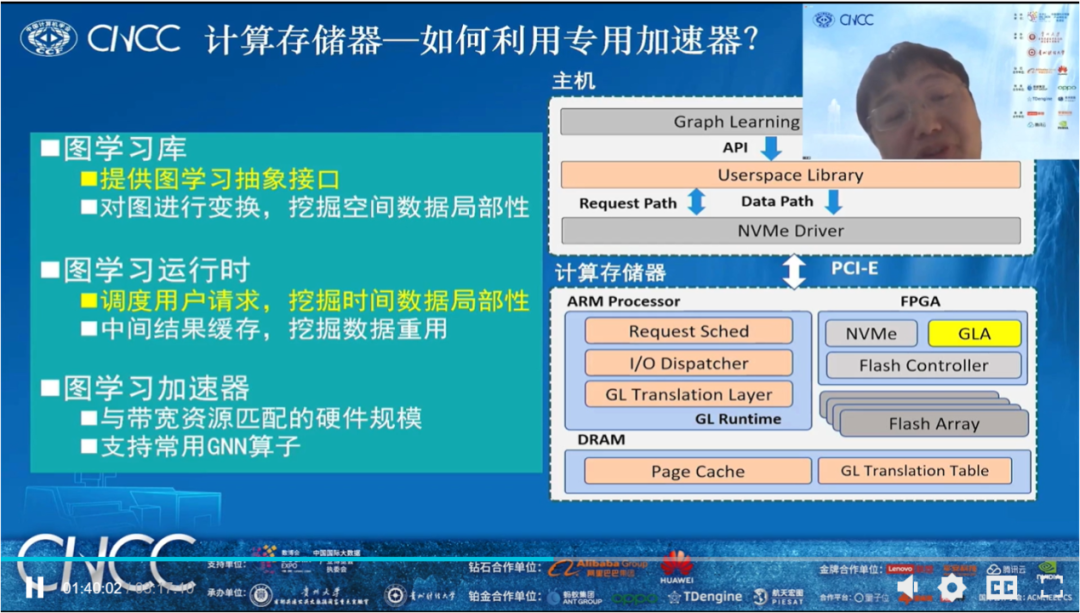
中国科学院计算技术研究所处理器芯片全国重点实验室副研究员刘成老师报告的题目是《基于计算存储器的图处理系统设计》。刘成老师首先介绍他们的工作研究了图处理的任务特征,从图的预处理、数据布局和访问、动态任务调度等不同的角度探索充分利用主机和计算存储器各自的计算、访存优势的协同设计方法;随后介绍他们实现的一个基于计算存储器的单节点图处理系统,相对于传统基于外存的图处理系统,其能够展示出了显著的性能加速。
上海交通大学副教授戴国浩老师报告的题目是《DIMMining:高效剪枝并行图挖掘近存架构》。戴国浩老师首先介绍到高性能图挖掘面领着如下挑战:(1)剪枝比较开销大:剪枝技术在图挖掘中被广泛,然而引入巨大的索引比较开销;(2)并行度低:图挖掘算法涉及大量并行度低的稀疏集合操作;(3)数据传输量大:图挖掘引入了比原始数据量大几个数量级中间数据传输。针对上述挑战,戴国浩老师团队提出了一种基于高效剪枝并行方法的图挖掘近存架构DIMMining。DIMMining提出的节点索引预比较技术可以有效降低剪枝操作的比较开销,并通过提出压缩位图和脉动合并阵列提升集合操作的并行度,最终实现基于DIMM的近存图挖掘架构,相对于CPU/FPGA加速2个数量级。

华为海思研究员陈鑫宇介绍了他在新加坡国立大学博士期间的一个研究工作,报告题目是《基于异构流水的高可扩展FPGA图计算》。陈鑫宇介绍到最近FPGA的内存子系统已经升级,包括在FPGA中引入HBM,有望进一步缓解内存瓶颈。然而,现代多信道HBM需要更多的处理流水线来充分利用其带宽潜力。由于资源效率不足,现有设计不能很好地扩展,导致HBM利用率不足。针对以上问题,陈鑫宇通过为图处理中的不同工作负载定制异构流水,从而有效地提高资源使用效率和性能。
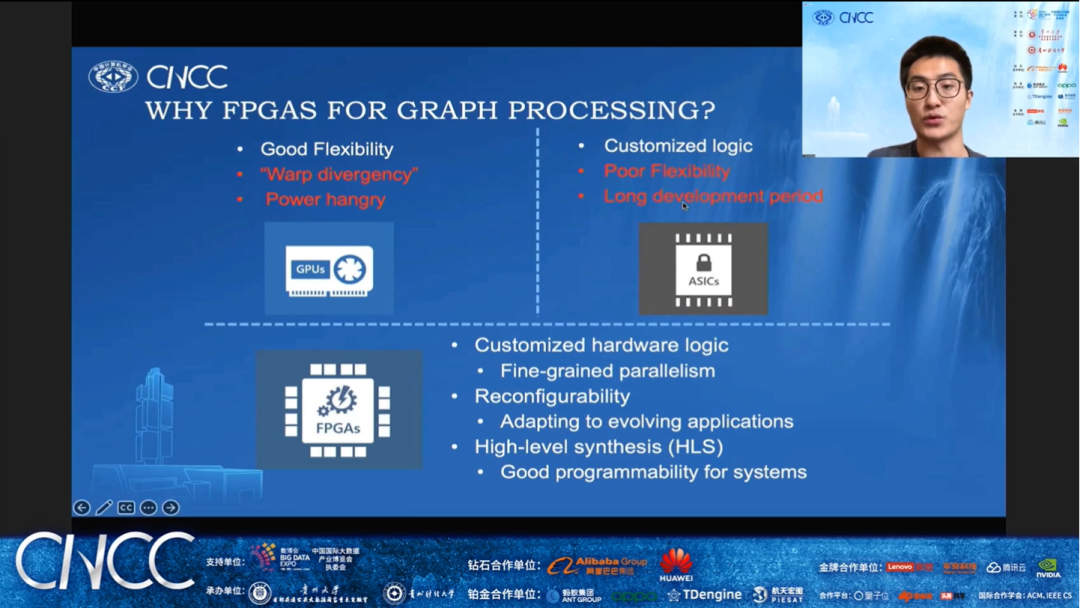
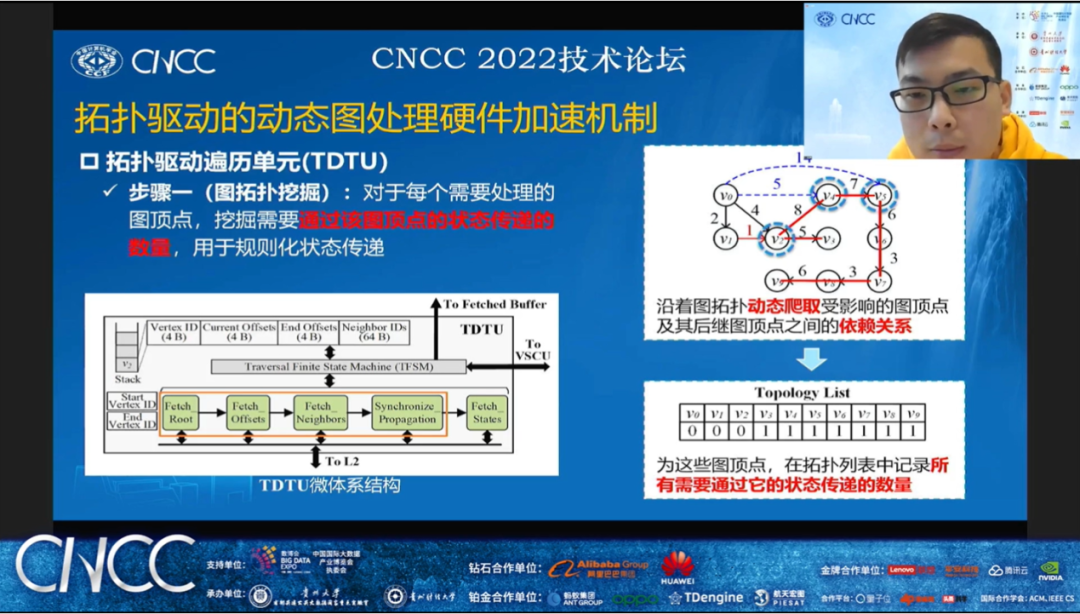
华中科技大学助理研究员赵进博士的报告题目是《拓扑驱动的动态图计算硬件加速机制研究》。赵博士首先介绍到现实世界的图通常随着时间动态改变的,为有效支持动态图处理,大量动态图处理系统采用增量计算的方式来快速获得最新图快照的计算结果。然而,在对动态图的每个图快照进行处理时,受图更新影响图顶点的最新状态值会沿着图拓扑不规则地传递,导致现有方法面领着严重的冗余计算和不规则内存访问的问题。针对以上问题,赵进博士提出了拓扑驱动的动态图处理硬件加速技术,通过高效规则化动态图处理中受影响图顶点的状态传递以及提高数据访问局部性,从而有效减少冗余计算和数据访问开销,保证动态图处理应用在众核处理器上的高计算效率。