 返回首页
返回首页

ADL136《分布式人工智能系统》开始报名

CCF学科前沿讲习班
The CCF Advanced Disciplines Lectures
CCFADL第136期
主题 分布式人工智能系统
2023年5月19日~21日 北京
本期CCF学科前沿讲习班ADL136《分布式人工智能系统》,将对分布式人工智能系统的最新进展进行深入浅出的讲解,从AI大模型、系统架构、软件工程、行业应用,以及用户和开发者的不同视角为听众介绍分布式人工智能系统的关键技术和前沿研究。相信学员经过本次讲习班,能够深入了解分布式人工智能系统的技术概况、主要挑战和未来演进趋势,开阔科研视野,增强实践能力。
本期ADL讲习班邀请了6位来自国内外著名高校与企业科研机构活跃在前沿领域的专家学者做主题报告。中国科大计算机学院/国家高性能计算中心(合肥)李诚副教授将介绍大模型分布式并行训练;爱丁堡大学助理教授麦络将解读如何设计高效的大规模机器学习系统;阿里巴巴PAI Research Lab负责人刁岚松将探讨AI大模型自动分布式系统开发的底层逻辑;微软亚洲研究院高级研发工程师高彦杰将介绍如何构建更鲁棒、高效和可调试的深度学习开发与系统;潞晨科技CTO卞正达将分享低成本训练AI大模型的挑战与实践;光年之外联合创始人袁进辉将基于OneFlow探讨重新思考分布式深度学习框架的设计。通过他们的教学,旨在带领学员实现分布式人工智能系统从基础技术,到前沿科研动态,再到典型应用场景的深入学习与思考。
学术主任:陈文光 清华大学 / 袁进辉 光年之外
主办单位:中国计算机学会
本期ADL主题《分布式人工智能系统》由清华大学教授陈文光和光年之外联合创始人袁进辉博士担任学术主任,邀请到李诚(中国科大计算机学院/国家高性能计算中心(合肥))、麦络(爱丁堡大学助理教授)、刁岚松(阿里巴巴PAI Research Lab负责人)、高彦杰(微软亚洲研究院高级研发工程师)、卞正达(潞晨科技CTO)做专题讲座。
活动日程:
具体日程将在会前通过邮件通知给参会者。

特邀讲者

李诚
副教授,中国科大计算机学院/国家高性能计算中心(合肥)
讲者简介:李诚,德国马普学会软件系统所(MPI-SWS)博士,中国科大计算机学院/国家高性能计算中心(合肥)副教授,博导,FCS、CCF THPC期刊青年编委。聚焦融合高性能计算基础系统软件研究,在 SOSP、OSDI、EuroSys、ATC、FAST、ASPLOS、SC、HPCA等计算机系统领域著名国际会议上发表论文40余篇。2019年入选ACM FCA成员。曾担任第14届/第21届 ChinaSys程序共同主席、SOSP 2017 学术海报程序共同主席、EuroSys 2021/ACM SIGMETRICS 2023论文出版共同主席、首届CCF计算机系统大会/芯片大会宣传主席等,长期参与SOSP、FAST、Middleware、DSN、ICDCS、SRDS等系统领域著名国际会议的程序委员会。获2022 AI 2000 Most Influential Scholar Honorable Mention in Computer Systems、2022年CCF分布式专委杰出青年学者、2021年ACM ChinaSys新星、2021年ACM中国新星提名等科研奖项。主讲《编译原理和技术》课程入选第二批国家级线下一流课程,获安徽省第五届青教赛工科组一等奖、第四届中国计算机教育大会计算机类教学资源建设特等奖(2项)、全国高校教学创新大赛安徽省二等奖等教学奖项。
报告题目:大模型分布式并行训练
报告摘要:随着摩尔定律的失效,人工智能和大数据等新兴应用对高性能处理需求的不断增加,计算机系统的设计与部署越来越多地从单机单处理器向多机多处理器的并行与分布式模态演变。并行与分布式系统逐渐发展成为促进互联网、云计算、大数据、人工智能等方向创新融合的主要支撑技术。然而,以深度学习为代表的新型并行与分布式计算面临严重的“数据墙问题”。随着模型规模的增大、模型结构的复杂化、训练数据体量的不断累积,数据交互已成为分布式并行训练最主要的性能瓶颈。李诚老师的科研工作以新场景和新硬件为驱动,解决异构并行、分布式计算中面临的数据搬运和同步瓶颈,成果被工业广泛关注。本报告将以超大规模深度神经网络模型的并行训练为例,介绍最新的科研成果及对未来技术趋势的思考。

麦络
助理教授,爱丁堡大学
讲者简介:麦络,2020年7月加入爱丁堡大学信息学院担任助理教授,领导大规模机器学习系统实验室。其研究兴趣包括计算机系统、机器学习和数据管理。麦络参与设计多个开源机器学习系统,包括 Quiver, KungFu和 TensorLayer 等。其科研成果发表在知名国际会议,包括OSDI,NSDI,USENIX ATC和 VLDB。麦络于2018年在帝国理工学院获得博士学位,博士期间获得谷歌奖学金资助。2018-2020年间,麦络在帝国理工学院担任博士后研究员,同时在微软研究院担任访问研究员。
报告题目:设计高效的大规模机器学习系统
报告摘要:在AI时代,我们需要大规模机器学习系统来完成各类AI模型的训练和部署。然而,现有系统无法充分理解AI模型独特的数据访问特征,同时也没有充分利用AI服务器上的GPU-NUMA架构。因此,时至今日,大规模机器学习依然需要耗费大量昂贵的硬件资源。在本次演讲中,我们将介绍两个高效的大规模机器学习系统,Ekko和Quiver,它们分别利用AI模型的数据访问特性和GPU-NUMA架构来实现了高效的模型训练和推理。Ekko和Quiver都已经被领先的AI实践者采用,并每天惠及数亿用户。

刁岚松
PAI Research Lab负责人,阿里巴巴
讲者简介:刁岚松于2003年从北京理工大学获得博士学位。博士期间的研究课题是硬件描述语言高层次综合技术。毕业后加入Cadence北京研发中心,从事spice仿真工具的研发。之后于2008年加入北京飘石科技有限公司,主持开发了国内首套商用RTL综合工具。后来在2017年加入阿里巴巴PAI团队。早期参与开发了FPGA CNN加速器软硬件系统。然后主持开发了AI大模型自动分布式系统TePDist。
报告题目:探究AI大模型自动分布式系统开发的底层逻辑
报告摘要:随着ChatGPT的大热,以GPT3/GPT4为代表的大模型的训练技术最近也受到越来越多人的关注。阿里巴巴PAI团队在大模型训练技术上长期投入,经过多年积累,开发了全自动分布式系统TePDist。工业界、学术界已经开发过多款大模型分布式系统,PAI团队开发的TePDist有什么不同?刁岚松博士将介绍TePDist的系统架构,并剖析TePDist的分布式策略探索算法,介绍算法选择背后的底层逻辑。同时,他还将分析分布式策略探索仍然面临的挑战,以及可能的解决方法。

高彦杰
高级研发工程师,微软亚洲研究院
讲者简介:微软亚洲研究院高级研发工程师。研究兴趣为深度学习平台工具和大数据系统的鲁棒性,效率与可调试性,积极参与人工智能系统教育。其中多项工作发表在著名系统与软件工程会议ICSE,ESEC/FSE,SoCC,并出版多部技术图书。
报告题目:构建更鲁棒、高效和可调试的深度学习开发与系统
报告摘要:近年来人工智能特别是深度学习与大语言模型技术得到了飞速发展,这背后离不开计算机硬件和软件系统的不断进步。在可见的未来,人工智能技术的发展仍将依赖于计算机系统和人工智能相结合的共同创新模式。但是我们观察到深度学习开发的生命周期中面临大量的程序缺陷,硬件与服务故障,造成大量作业难以稳定与高效完成执行,影响生产力和造成资源浪费。在本次报告里,我们将介绍关于深度学习程序缺陷,AI平台质量问题的实证研究,以及如何通过人工智能工具和系统设计缓解与规避相应的缺陷,故障,让深度学习作业和系统更加稳定与高效的执行。

卞正达
CTO,潞晨科技
讲者简介:潞晨科技 CTO,新加坡国立大学、西安交通大学硕士,对大规模深度学习和分布式计算有深入研究,Colossal-AI 主要贡献者之一,曾在 SC、TON 等顶级会议期刊上发表一作论文。
报告题目:低成本训练AI大模型的挑战与实践
报告摘要:AI模型在几年内已增大万倍,远超硬件能力数倍的增长,如何高效利用分布式技术实现AI大模型的并行训练加速已成为行业关键痛点。在本次报告中,我将与大家介绍面向AI大模型时代的通用开发系统Colossal-AI,它通过高效多维并行、异构内存管理、大规模优化库、自适应任务调度等方式,仅需几行代码,便可与已有项目结合,高效快速部署AI大模型训练,为企业降低AI大模型落地应用成本。

袁进辉
联合创始人,光年之外
讲者简介:袁进辉,光年之外联合创始人。清华大学计算机系博士、博士后,师从张钹院士。清华大学优秀博士学位论文奖获得者 , 曾任微软亚洲研究院主管研究员,专注于大规模机器学习平台及基于异构集群的深度学习系统研发,发明了当时世界上最快的主题模型训练算法和系统LightLDA。2017年发起和主导研发了开源深度学习框架OneFlow,在分布式深度学习系统编程易用性和高效性方向设计了一系列新方法,并为国内外主流深度学习框架广泛跟进和效仿。兼任之江实验室天枢开源开放平台架构师,北京智源人工智能研究院大模型技术委员会委员。
报告题目:OneFlow:重新思考分布式深度学习框架的设计
报告摘要:近来,大规模预训练模型备受关注,但多数通用深度学习框架仅支持数据并行,还不直接支持大模型所需要的模型并行、流水并行等技术,只能基于框架定制开发专用软件系统(如Megatron-LM, DeepSpeed等)来满足需求,分布式训练的易用性和通用性大打折扣,能不能让通用深度学习框架直接满足这些需求呢?本次课程对这个问题展开探讨:(1)梳理和总结大模型带来的技术挑战,讨论主流开源解决方案的技术原理和优缺点;(2)基于 OneFlow 实践讨论如何直接、统一、简洁地实现大模型训练所需要各项关键技术,让大规模分布式深度训练像在单卡上编程一样简单;(3)NCCL 作为一款高效灵活的集合通信库已成为分布式深度学习的标配,但其非抢占式调度机制在大模型场景非常容易导致死锁,我也将讨论如何通过抢占式调度来实现一款能避免死锁的集合通信库。
学术主任

陈文光
教授,清华大学
陈文光,CCF杰出会士、CCF副秘书长、YOCSEF荣誉委员,2020年“CCF杰出贡献奖”获得者。他是清华大学计算机系教授,ACM中国理事会常务理事。他的主要研究领域为操作系统、程序设计语言与并行计算。他曾获得国家科技进步二等奖、国家教委科技进步二等奖和北京市科技进步二等奖各一次。陈文光一直担任CCF CSP(计算机软件能力认证)技术委员会主席,负责组织制定CSP认证标准,主持CSP命题和评价,为CSP的权威性、专业性作出了杰出贡献。为此,陈文光获得了2020年“CCF杰出贡献奖”。

袁进辉
联合创始人,光年之外
袁进辉,光年之外联合创始人。清华大学计算机系博士、博士后,师从张钹院士。清华大学优秀博士学位论文奖获得者 , 曾任微软亚洲研究院主管研究员,专注于大规模机器学习平台及基于异构集群的深度学习系统研发,发明了当时世界上最快的主题模型训练算法和系统LightLDA。2017年发起和主导研发了开源深度学习框架OneFlow,在分布式深度学习系统编程易用性和高效性方向设计了一系列新方法,并为国内外主流深度学习框架广泛跟进和效仿。兼任之江实验室天枢开源开放平台架构师,北京智源人工智能研究院大模型技术委员会委员。
时间:2023年5月19日-21日
地址:北京•中科院计算所一层报告厅(北京市海淀区中关村科学院南路6号)
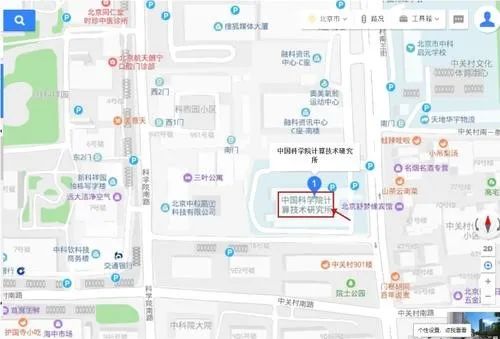
报名须知:
1、报名费:CCF会员2800元,非会员3600元。食宿交通(费用)自理。根据交费先后顺序,会员优先的原则录取,额满为止。应部分学员的要求,本期ADL线上同步举办,线上线下报名注册费用相同。线上会议室号和密码将在会前3天通过邮件发送。
2、报名截止日期:5月17日。报名请预留不会拦截外部邮件的邮箱,如qq邮箱。会前1天将通过邮件发送会议注意事项和微信群二维码。
3、咨询邮箱 : adl@ccf.org.cn
缴费方式:
在报名系统中在线缴费或者通过银行转账:
银行转账(支持网银、支付宝):
开户行:招商银行北京海淀支行
户名:中国计算机学会
账号:110943026510701
请务必注明:ADL136+姓名
报名缴费后,报名系统中显示缴费完成,即为报名成功,不再另行通知。
报名方式:
请选择以下两种方式之一报名:
1、扫描(识别)以下二维码报名:

2、点击报名链接报名:
https://conf.ccf.org.cn/ADL136





