 返回首页
返回首页

何水兵:面向AI系统的存算技术论坛 | CNCC专家谈
在即将于今年10月26-28日在沈阳举办的CNCC2023期间,在130个涵盖人工智能、安全、计算+、软件工程、教育、网络、芯片、云计算等30个热门专业领域的技术论坛上,包括国际知名学者、两院院士、产学研各界代表在内的700余位报告嘉宾将着力探讨计算技术与未来宏观发展趋势,为参会者提供深度的学术和产业交流机会,当中不乏在各领域深具影响力的重磅学者专家亲自担纲论坛主席。
本专题力邀CNCC2023技术论坛主席亲自撰稿,分享真知灼见,带你提前走进CNCC,领略独特专业魅力!


本期特别嘉宾:
何水兵 CCF杰出会员,浙江大学研究员、博导
作者:CNCC2023【面向AI系统的存算技术】技术论坛主席 何水兵
AI技术赋能各行各业
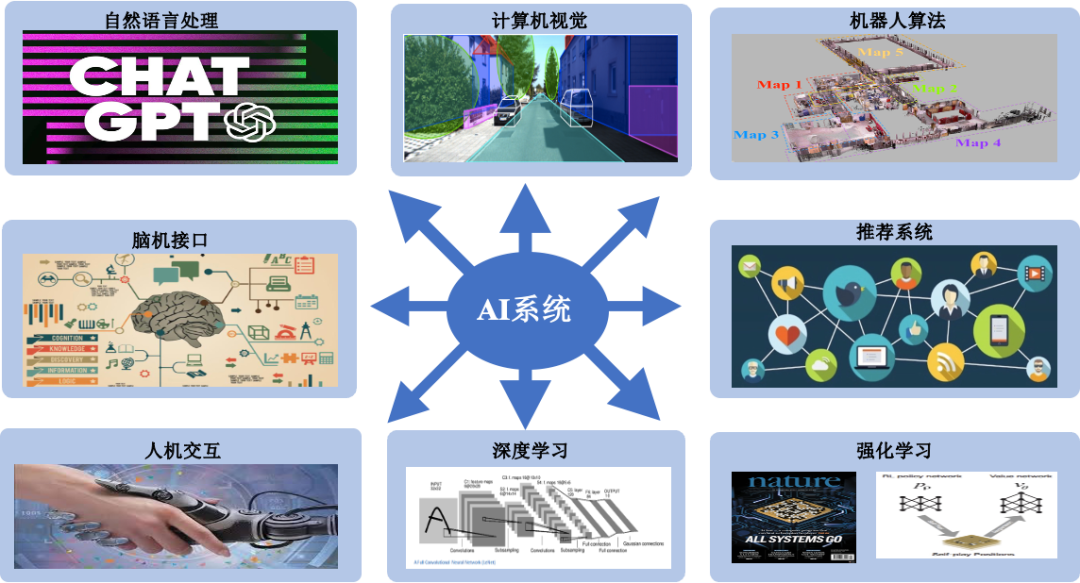
图1:AI技术赋能各行各业
随着社会经济的发展和科技水平的提高,人工智能(Artifical Intelligence, AI)技术已经出现在人们生活的方方面面,如自然语言处理、计算机视觉、脑机接口、推荐系统等等(图1)。随着ChatGPT、Stable Diffusion等新型AI现象级应用的出现,通用AI进入了大模型时代。垂域应用和大模型结合的创新成果如雨后出笋般快速涌现,大模型在社会生活方方面面展现出了前所未有的威力。
AI系统面临的挑战
AI技术的快速发展离不开计算机硬件平台和软件系统(简称AI系统)的大力支撑。高效的AI系统能够有效应对AI任务的运算能力(算力)需求,提升应用运算效率,降低用户成本,从而助力AI技术的突破。在“数据、算法、算力”这三架AI发展的马车之中,算力是整个AI技术发展的基座。然而,随着AI模型参数量与数据集规模的井喷式增长,当前AI系统面临着“算力、存储、网络和可靠性”等方面的挑战。
- AI系统面临巨大的算力需求:目前AI模型层数较深且计算复杂,需要消耗巨大的算力。OpenAl的数据显示,从2012年到2020年,其算力消耗平均每3.4个月就翻倍一次,8年间算力增长了30万倍[1](如图2)。2023年3月推出的多模态大模型GPT-4, 训练时的算力需求甚至达到了惊人的每秒2.15×1024 FLOPS[2]。不断增长的算力需求,使得AI计算中心面临着前所未有的算力挑战。

图2:2012年以来算力需求增长了超过30万倍
- AI系统面临巨大的存储挑战:以大模型为代表的AI训练具有参数众多并且输入数据集较大的特点。例如, GPT-4 模型具有1.8 万亿的模型参数且需要13万亿的Token作为输入数据集[2]。AI系统需要高效的存储系统来存储和读取这些大量的数据。然而,AI模型的数据大小呈现出逐年上升的趋势 [3](如图3),与此同时,存储硬件性能增长的速度远滞后于GPU算力提升的速度,因此,存储访问日益成为一些AI应用的性能瓶颈。例如,在美国橡树岭国家实验室的深度学习气候预测中,其使用的分布式文件系统仅仅能提供1%的理想带宽(1.16 TB/s);在美国阿贡国家实验室的深度学习应用中,I/O访问时间最高占据了90%的总执行时间,成为了性能瓶颈。
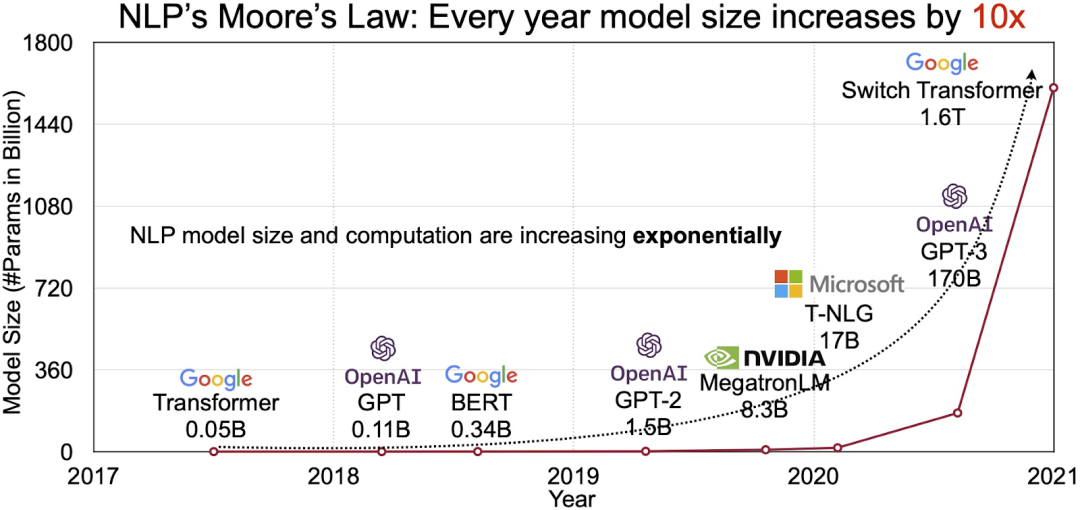
图3:AI模型增长趋势
- AI系统具有较高网络传输需求:由于单一计算节点无法满足大规模AI算力需求,目前AI中心往往利用网络将多个GPU服务器连接起来进行分布式机器学习。在分布式机器学习中,数据需要在多个机器间进行通信。如果网络传输速度较慢或不稳定,整个GPU系统的计算效率将会极大降低。如图4所示,较差的网络传输往往能降低一半的模型训练效率,对宝贵的硬件资源造成极大的浪费[4]。

图4:网络通信限制模型的训练性能
- AI系统具有较强的可靠性需求:由于多设备的参与以及长时间的运行,AI应用往往面临较高的出错率。例如,OPT-175B模型在训练的过程中使用了992张A100 GPU,并在两个月的训练时间内故障超过110次[5]。类似的现象同样出现在BLOOM模型的训练过程中[6]。频繁的故障带来硬件资源的浪费,增加应用执行的成本,因此需要高效的系统故障恢复机制,保证训练的稳定持续执行。
新型AI存算技术
为了解决上述挑战,我们迫切需要寻求新的AI存算技术,从存储、计算、网络等诸多方面对现有AI系统进行升级改造。按照系统架构的不同,可分为两种思路:一是对经典冯·诺伊曼架构下的AI系统进行优化,二是探索开发基于新型存算一体架构的AI存算系统。上述两种架构的对比如图5所示。
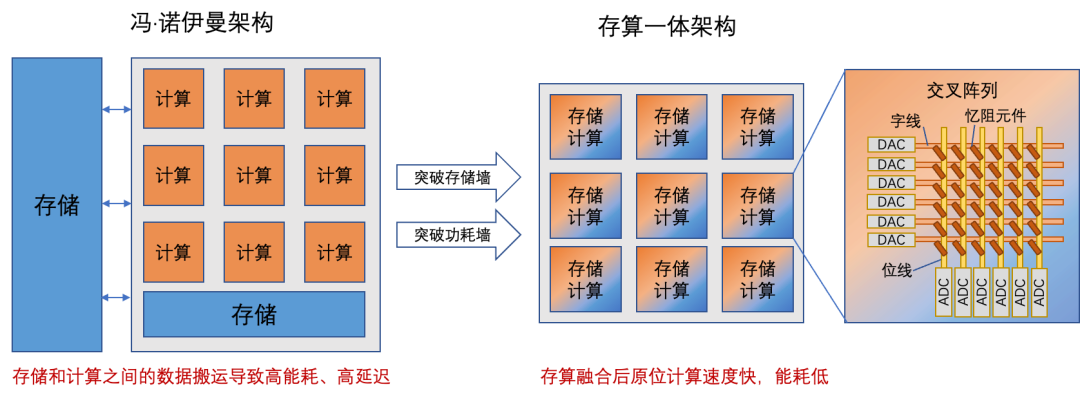
图5:传统冯·诺伊曼架构 v.s. 新型存算一体架构
(1) 优化经典架构
为了满足前所未有的算力和存储需求,现有AI中心一般采用分布式架构(如图6),将多个处理器、加速器或者存储设备能力聚合起来,进行大规模机器学习[7]。目前涌现出了面向AI的分布式计算、分布式存储以及新型存储技术等方面的研究,重点针对AI模型的特有计算特征和访存模式构建高效的底层计算调度系统、存储系统、内存系统等。此外,高效的网络通信技术也是当前AI系统研究的热点问题。
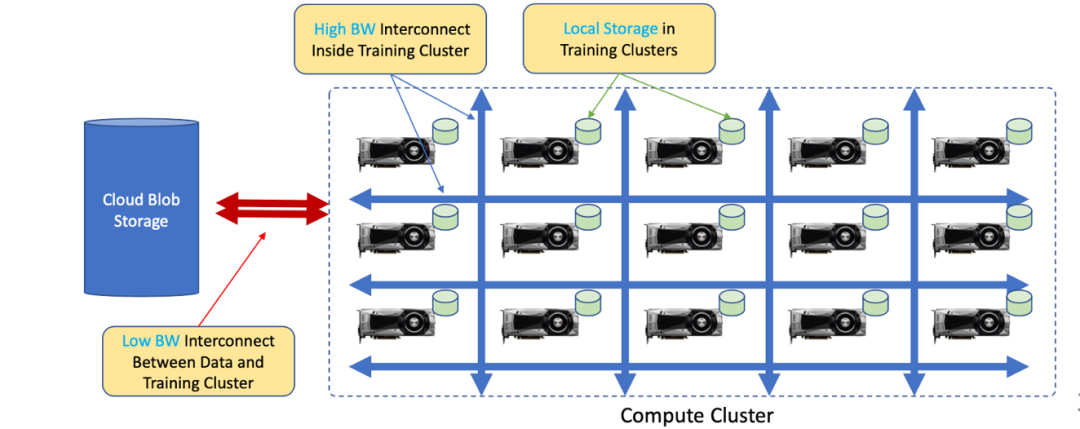
图6:经典分布式架构
a.分布式计算
AI中心一般部署多个GPU服务器来满足AI模型巨大的算力需求。每个服务器上配备若干加速AI运算的GPU,整个集群系统可能包含成千上万的GPU。例如,为了训练GPT-4,OpenAI使用了25000块A100,构建了成本高昂的大规模分布式GPU集群。然而,目前AI系统中硬件资源利用率依然不高,如GPU的利用率通常在30%以下,这导致了巨大的资源浪费和较高的算力成本。因此,现有AI系统仍迫切需要开发高效的软硬件技术,进一步提升分布式机器学习的效率。
b.分布式存储
为了满足AI模型不断增长的带宽需求,AI中心往往将模型数据集部署在共享的分布式存储之上。例如,在微软的数据中心中,97.3%的训练任务从其旗下的Azure分布式云存储系统中进行数据的存储和读取。然而,由于AI应用的数据量在不断增加,目前分布式存储系统提供的I/O带宽依然有限。因此,开发更高效的存储系统加速技术,如结合AI数据访问特征的数据预取或者缓存方法,目前成为了AI存储系统的研究热点。此外,一些新型存储架构和设备也成为重点关注的问题。
c.新型存储技术
一些AI应用对于训练、推理的实效性具有严格要求,基于磁盘的存储系统难以满足AI应用的极限存储带宽需要。新型的非易失性内存(Non-volatile memory, NVM),具有高带宽、低延迟特征,同时具有外存的持久性,为设计高效AI存储系统提供了新的思路。然而,NVM具有自己固有特征,因此如何高效利用NVM技术,感知设备特性,减少软件开销,针对AI应用在系统和用户软件层进行专门优化,成为了AI新型存储技术的前沿研究方向。
d.网络加速技术
提升网络通信效率是加速整个分布式机器学习性能的一种有效方法。基于智能网络设备的通信加速技术目前在AI系统领域受到了广泛关注。这些方法通过融合新型智能网络设备,如基于FPGA智能网卡和可编程智能交换机等,对数据进行网内计算和处理,从而降低AI计算过程中的数据传输大小和网络延迟,加速整个AI模型的训练或推理过程。
(2)设计新型架构
传统基于冯·诺伊曼架构的AI系统受到存、算分离的计算范式限制,无法平衡日益悬殊的存储和计算发展差距,始终面临存储墙、功耗墙问题。为此,以新型存算一体架构为代表的非冯·诺依曼架构被提出。通过引入存算一体芯片、类脑芯片等硬件,新型存算一体架构实现将存储和计算模块的融合,有效避免数据在存储和计算单元间反复搬运导致的存储墙和功耗墙问题,提高计算效率。
a.存算一体芯片
新兴的存算一体芯片,如忆阻器等,将数据的存储和计算集成在同一模块内部,通过原位计算极大降低数据访问延迟和能耗(图7所示),可有效满足未来大规模人工智能应用场景的存算需求。然而,相关技术仍处于起步阶段,离产业化落地还需很长的一段路要走。如何通过电路、架构、算法等角度展开一系列技术创新,打通从底层硬件到顶层应用之间的各个关键环节,设计出面向AI的高效一体化存算系统,仍是一个亟需解决的问题。

图7:存算一体计算芯片
b.类脑计算芯片
类脑计算作为存算一体的重要分支,通过借鉴神经细胞能同时进行计算和存储的特性,实现了存储与计算的深度融合,如图8所示。这种融合构建了神经拟态类脑芯片,利用脉冲神经网络进行训练和推理,使得处理复杂数学问题和图像识别等任务更加高效,具有极高的研究价值。目前这一方向国内外也在积极探索之中。
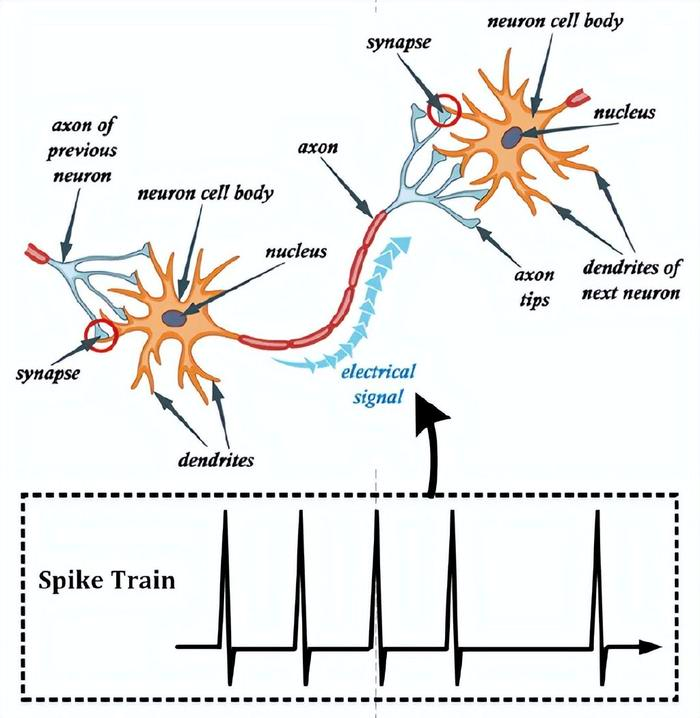
图8:类脑计算中的脉冲神经网络
四、 技术论坛是促进领域发展的重要手段
随着AI模型的参数量与计算规模井喷式增长,驱动AI模型训练与推理的存算技术也需不断推陈出新。日益发展的AI模型在计算与存储系统领域会带来哪些新的问题与挑战?新型AI存算技术又将往何处发展?
敬请关注本年度CNCC大会组织的“面向AI系统的存算技术,未来系统发展新趋势”论坛。本论坛邀请近年来具有代表性成果的杰出学者和头部企业技术负责人进行分享,围绕新型AI存算技术的关键要素展开讨论,探索新型应用、计算框架、存算架构、云基础设施等多个技术领域的趋势和最新进展,给大家提供良好的学术交流平台,欢迎加入!让我们共同促进AI系统领域的发展和进步!

CNCC参会报名
论坛名称:【面向AI系统的存算技术】
举办时间:10月26日下午
论坛主席:何水兵 CCF杰出会员,浙江大学研究员、博导
共同主席:王喆锋 华为云AI系统创新实验室技术专家
想了解更多关于CNCC2023技术论坛信息,欢迎观看CCF公众号【CNCC专家谈】专题及CCF视频号【CNCC会客厅】直播,我们将陆续邀请本届CNCC技术论坛的论坛主席或重磅嘉宾,围绕今年CNCC涉及到的热门话题进行研讨交流,亲自带观众走进CNCC,敬请随时关注!





