 返回首页
返回首页

CNCC | 邀您共话“新一代人工智能背景下语音技术的机遇与挑战”


CNCC2023将于10月26日至28日在沈阳举行,会议期间将举办129场技术论坛,涵盖人工智能、安全、计算+、软件工程、教育、网络、芯片、云计算等30余个方向。本文特别介绍将于10月26日举办的【新一代人工智能背景下语音技术的机遇与挑战】技术论坛。
本论坛聚焦语音技术在新一代人工智能背景下的发展趋势和前沿问题,围绕语音处理与大数据、语音理解与大模型、语音生成与AIGC、语音技术与应用新需求等,邀请国内外知名的技术专家和学者从学术与产业角度深入探讨语音技术如何应对新的机遇与挑战。
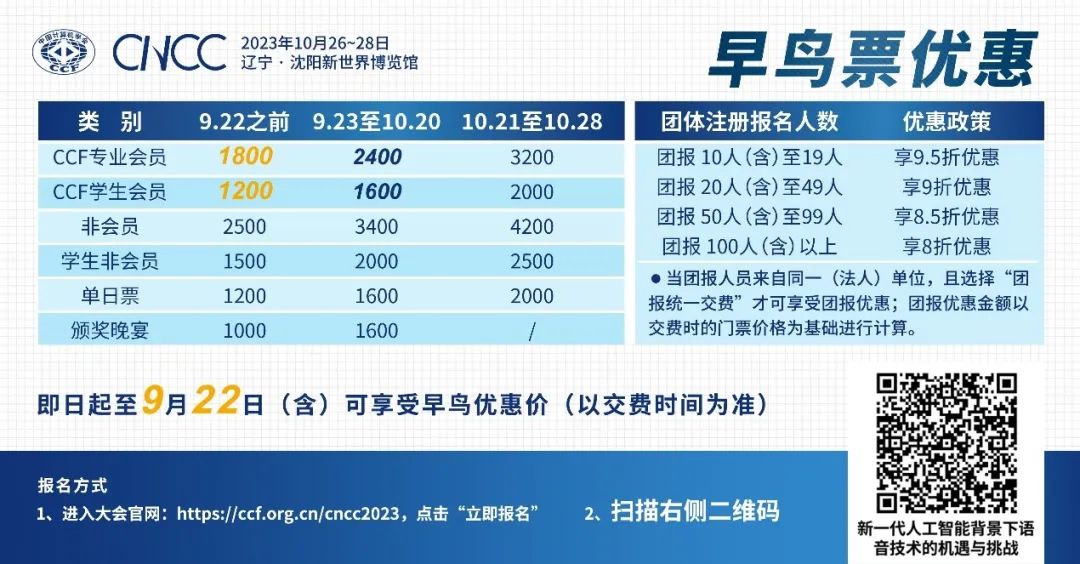
报名及了解更多技术论坛信息请识别下图二维码进入CNCC2023官网。目前早鸟票限时优惠报名正在进行,抓住机会立享大幅优惠!

语音技术是人工智能(AI)的重要分支,它让计算机能够理解和生成人类的语音,实现与人类自然、流畅、高效的交互。语音技术涵盖了语音识别、语音合成与转换、声纹识别、情感分析等多个领域,在智能客服、智能教育、智能家居等多个场景中展现出巨大的价值和潜力。随着新一代人工智能技术的不断发展和创新,语音技术也面临着新的挑战和机遇。
本论坛将聚焦语音技术在新一代人工智能背景下的发展趋势和前沿问题,从语音理解、语音与大模型的结合、面向AIGC的语音生成、语音技术在人机交互服务中的应用等方面展开讨论。本论坛邀请了来自香港中文大学(深圳)、清华大学、复旦大学、天津大学、上海交通大学、科大讯飞、喜马拉雅等国内外知名的语音技术专家和学者,他们将分享他们在语音技术领域的最新研究成果和经验,以及对未来语音技术发展方向的展望。本论坛旨在为参与者提供一个交流学习、探索创新、寻求合作的平台,促进语音技术在新一代人工智能背景下的进一步发展。

论坛安排

顺序 | 时间 | 主题 | 主讲嘉宾 | 单位 |
1 | 13:30- 14:20 | 听觉注意力的理论与算法 | 李海洲 | 香港中文大学(深圳) |
2 | 14:20- 15:15 | 说话人声音模仿与鉴别技术 | 陶建华 | 清华大学 |
3 | 15:15- 15:30 | 茶歇 | ||
4 | 15:30- 16:20 | SpeechGPT:让大语言模型具有内生的语音对话能力 | 邱锡鹏 | 复旦大学 |
16:20- 17:30 | Panel嘉宾 | 李海洲 | 香港中文大学(深圳) | |
陶建华 | 清华大学 | |||
邱锡鹏 | 复旦大学 | |||
党建武 | 天津大学 | |||
俞 凯 | 上海交通大学 | |||
高建清 | 科大讯飞 | |||
卢 恒 | 喜马拉雅 | |||

论坛主席


贾珈
CCF语音对话与听觉专业委员会秘书长
清华大学教授/博导、计算机科学与技术系党委书记
CCF杰出会员,国家级青年人才称号获得者,主要研究兴趣是情感计算和人机语音交互。曾于2023年获中国多媒体大会(ChinaMM)最佳论文奖,日本大川基金项目资助;2020年获得国家级青年人才称号,入选北京智源人工智能研究院青年科学家;2018年获ACM SIGMM Emerging Leaders、ACM Multimedia Best Demo Award、IJCAI Early Career Spotlight;2019年获中国电子学会科技进步一等奖;2016年和2009年分别获教育部科技进步二等奖;2012年获ACM Multimedia Grand Challenge Prize。
共同主席

谢磊
西北工业大学教授/博导
CCF语音对话与听觉专业委员会常务委员。曾在比利时布鲁塞尔自由大学、香港城市大学和香港中文大学从事研究工作。获得教育部"新世纪优秀人才支持计划",陕西省青年科技新星、西安市青年科技奖、亚太信号与信息处理协会Distinguished Lecturer等荣誉。研究兴趣为智能音频与语音处理技术,包括语音增强与声音分离、语音识别、语音与歌声合成、声纹识别、多模态处理等。在包括IEEE/ACM Transactions on Audio, Speech and Language Processing、 IEEE Transactions on Multimedia, ACL, Interspeech, ICASSP、ACM Multimedia在内的重要期刊和会议上发表论文280余篇,众多研究成果已在企业获得应用落地,获得美团科研合作实践奖、华为优秀技术合作成果奖、华为云优秀创新合作团队奖等。谢磊教授当前担任IEEE语音和语言技术委员会(IEEE SLTC)委员、中国计算机学会语音听觉与对话专委会常务委员、IEEE/ACM Transactions on Audio, Speech and Language Processing高级领域副主编(SAE)等。

吴志勇
清华大学深圳国际研究生院副研究员/博导
CCF高级会员,CCF语音对话与听觉专业委员会秘书组成员。清华大学-香港中文大学媒体科学、技术与系统联合研究中心副主任。研究兴趣为智能语音交互技术。承担国家自然科学基金、香港特区政府研究资助局基金、国家社会科学基金等多项课题。获2009及2016年度教育部科学技术进步奖,2021年度北京市科学技术进步奖。指导的学生多人次获得优秀学位论文、国家奖学金、优秀毕业生,在2017全球极客大赛“AI仿声验声攻防赛”及ICASSP 2023语音信号质量增强挑战赛中斩获桂冠。获得2020年度清华大学年度教学优秀奖,当选2022年度清华大学第十八届“良师益友”。

论坛讲者


李海洲
新加坡工程院院士
香港中文大学(深圳)校长讲座教授、数据科学学院执行院长
新加坡国立大学终身教授,德国不来梅大学卓越讲座教授
IEEE Fellow,ISCA Fellow,教育部长江学者。李海洲1990年获得华南理工大学博士学位,曾任法国国家科学研究中心研究员、苹果公司新加坡研究中心语音处理实验室研究主任、Lernout & Hauspie亚太区研究总监、言丰科技新加坡总经理兼集团副总裁、新加坡科技研究局通信与资讯研究院首席科学家、研究总监。在2006年—2021年分别担任南洋理工大学和新加坡国立大学教授。李教授的研究领域包括语音信息处理、自然语言处理、类脑计算、人机交互,他于2013年获新加坡共和国科学技术最高荣誉-新加坡总统科技奖。李教授曾经担任国际语音通信学会主席(2015-2017),IEEE/ACM Transactions on Audio, Speech and Language Processing总编(2015-2018),ACL 2012,INTERSPEECH 2014,ICASSP 2022的大会主席,他也是现任IEEE信号处理学会副会长(2024-2026)。
听觉注意力的理论与算法
面对复杂的声学场景,人通过眼睛和耳朵的紧密配合、并由大脑协调而实现对目标声源的选择,这称为听觉注意力。神经科学和听觉心理学的研究发现,人的听觉注意力是通过自上而下和自下而上的注意力交互,形成一个像过滤器一样的注意力接收域。这个报告中,我们先回顾人的听觉注意力的一些研究成果,激发机器学习算法的设计, 并讨论听觉注意力算法在语音增强、说话人提取、语言提取等应用课题中的实践。

陶建华
CCF会士、常务理事,CCF语音对话与听觉专委会副主任
清华大学自动化系教授/博导
国家杰出青年基金获得者,国家级领军人才,享受国务院政府特殊津贴。主要从事语音技术、数据认知、模式识别等方向,在国内外主要期刊或会议上发表论文300余篇,先后负责国家863重点项目、国家重点研发计划项目、国家自然科学基金重点项目、中科院先导项目、国家发改委项目等重点科研任务。研究成果获2022年中国人工智能学会吴文俊技术发明特等奖、2021年中国电子学会技术发明一等奖、2018年中国电子学会技术进步一等奖,并多次在国内外学术会议上获奖。目前担任中国人工智能学会常务理事等,并担任Speech Communication、计算机研究与发展等多个主要国内外期刊编委,同时担任Interspeech、ACII、IEEE ICSP、IEEE MLSP等会议大会主席或程序委员会主席。
说话人声音模仿与鉴别技术
高度拟人化和个性化的人物声音模仿技术,正在通信、教育、金融、社交、娱乐等领域发挥重要作用,人们可享受到高质量和定制化的语音服务,报告将介绍并展示近几年在迁移学习、生成式网络模型等帮助下的说话人声音模仿技术的最新成果。与此同时,逼真的个性化声音模仿能力,在造福人类的同时,也不可避免带了安全风险,技术的恶意利用与传播会对国家和社会造成严重危害,已受到世界各国政府的高度重视,报告还将系统性的介绍伪造声音鉴别技术,分别在伪造声音鉴别方法、伪造溯源分析方法、面向复杂场景的声音生成与鉴别对抗博弈机制等方面进行深入分析和阐述。

邱锡鹏
复旦大学计算机学院教授/博导主要研究方向为自然语言处理基础技术和基础模型,曾获中国科协青年人才托举工程项目、国家优青等项目,获钱伟长中文信息处理科学技术奖一等奖,“爱思唯尔2022中国高被引学者”,主持开发了开源框架FudanNLP和FastNLP,已被国内外数百家单位使用,发布了MOSS、CPT、BART-Chinese等中文预训练模型,在中文模型中下载量排名前列。目前MOSS已经成为国内影响力最大的开源大型语言模型之一。
SpeechGPT:让大语言模型具有内生的语音对话能力
从GPT-4开始,一系列多模态大语言模型的工作都是接受多模态输入,产生文本输出的范式,没有产生多模态输出的能力。但是这离AGI还有一定的距离,本报告介绍SpeechGPT,它具有内生的跨模态能力,既能接受跨模态输入,也能产生跨模态输出的大语言模型。SpeechGPT突破了传统语音到语音对话流水线方式 (ASR+LLM+TTS) 的束缚,实现了模态之间的知识传递,不需要额外的ASR和TTS系统也能和LLM直接进行语音对话。

Panel嘉宾


党建武
CCF语音对话与听觉专业委员会主任
天津大学智能与计算学部教授/博导

俞凯
CCF语音对话与听觉专业委员会副主任
上海交通大学计算机系特聘教授/博导、苏州人工智能研究院执行院长
思必驰公司创始人、首席科学家

高建清
科大讯飞AI研究院常务副院长

卢恒
喜马拉雅首席科学家,珠峰实验室负责人
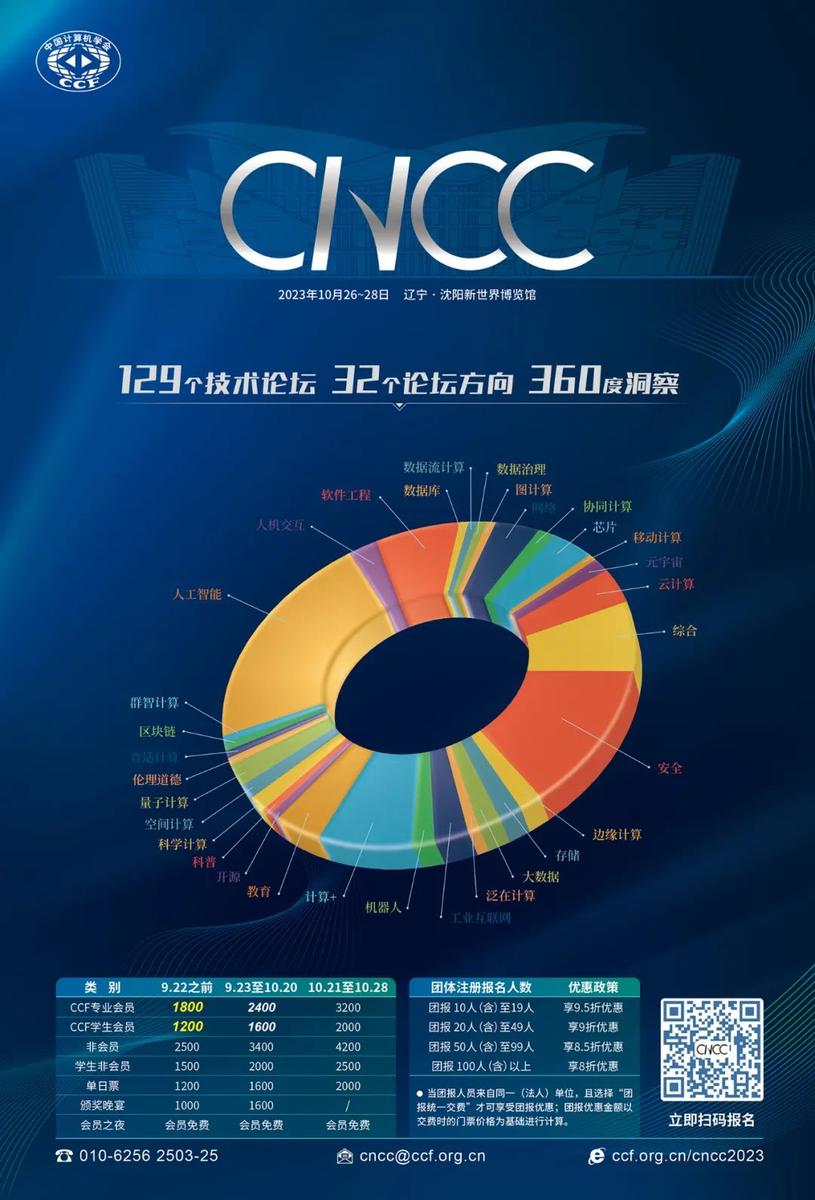
今年恰逢CNCC创办20周年。二十年来,CNCC已逐渐发展到涵盖数十个方向129场技术论坛,700余位国内外讲者积极参与,超过13000人注册的计算领域年度盛会。二十载不断超越,作为国内计算领域参会人员众多,规模大,水平高的年度盛会,CCF将精心筹划,为参会者带来一场前沿碰撞、展望未来的技术盛宴,让每位参会者都能在CNCC这个超大体量专业平台上提升自身的专业价值,获得前行的动能!等你来,马上行动,欢迎参会报名!







