 返回首页
返回首页

回放:网络生态治理-社交媒体上的虚假信息识别|CNCC论坛分享
CNCC2022技术论坛“网络生态治理-社交媒体上的虚假信息识别”于12月9日在线成功举办。该论坛被评为CNCC2022优秀技术论坛。点击文末左下角“阅读原文”或扫码(仅对CNCC注册参会者开放),可观看论坛视频回放。

扫码观看CNCC技术论坛回放

本次论坛由中国科学院信息工程研究所虎嵩林研究员和周薇高级工程师共同担任执行主席。本次论坛聚焦网络的虚假信息识别,同时非常荣幸地邀请到了假信息检测领域的领军人物、美国亚利桑那州立大学刘欢教授,香港浸会大学宋韵雅教授,哈尔滨工业大学秦兵教授,中科院计算所曹娟研究员,清华大学长聘副教授刘知远老师共5位特约讲者参与本次活动,就打击社交媒体上的虚假信息及其挑战、虚假信息跨学科分析、虚假识别中的社会情绪智能、多模态虚假信息检测方法、对抗虚假生成的大模型安全伦理等话题进行了深入浅出的分享与讨论,引发了在场观众的广泛讨论与强烈共鸣。

中科院信工所虎嵩林研究员主持论坛
美国亚利桑那州立大学计算机科学系讲席教授刘欢以《打击社交媒体上的虚假信息及其挑战》为主题进行报告,刘欢教授围绕社交媒体中虚假信息智能分析的挑战为主线,首先介绍其团队在虚假信息检测和识别任务中取得的一系列代表性成果,包括信息内容的虚假信息检测、跨领域虚假检测、虚假信息可解释性研究等等,其次就如何在社交媒体上建立一个更健康和谐的生态系统对虚假信息打击提供切实可行的解决思路,最后提出了下一步工作的挑战问题。

在2018年3月的一篇《Science》文章指出“假新闻比真相传得更深、更广、更远”。这些独特传播现象的背后,仍然隐藏着亟待我们发现的内在原理。本质上,“虚假信息处理”属于跨学科的问题,结合信息学、传播学、心理学、社会学,以跨学科的视野对虚假信息治理进行探索和研究,能够更加有效地在复杂的环境中识别虚假信息、发展合适的纠错方法、提供有效的策略。来自香港浸会大学传理学院人工智能与媒体研究实验室的宋韵雅主任和大家分享了《信息污染的跨学科研究前沿》主题报告,宋韵雅教授围绕虚假信息治理的交叉学科研究潜力,以香港为背景从信源、传播规律等传播学角度观察和分析涉港事件及疫情中的信息流行病。报告中探讨了如何将计算方法(例如机器学习)和各种社会科学方法(例如实验、深度访谈和社交网络分析)相结合,并全面阐述虚假信息跨学科分析的必要性。从分析到案例,给跨学科的虚假信息治理带来了一场视听盛宴。
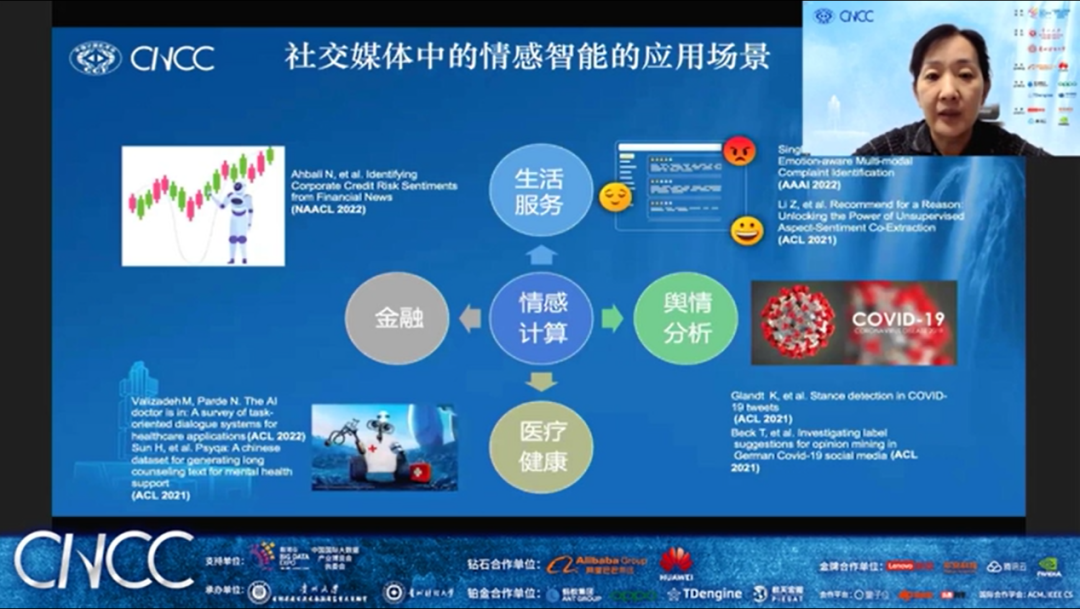
哈尔滨工业大学社会计算与信息检索研究中心秦兵教授和大家分享了《社交媒体中的情感智能》主题报告。秦兵教授从什么是社交媒体中的情感智能作为引言向大家介绍了社交媒体中情感内容的4大特点,然后从虚假信息检测、情绪分析和立场分析三个方面针对事件、实体等进行具体科学分析,最后对社交媒体的情感智能分析进行了总结和展望。秦兵教授的报告从虚假信息治理的另一维度给我们带来了全新的思考。
虚假信息打破了人们对“有图有真相”的传统认知。在信息内容辨识方面,我们需要对信息内容的深入理解、对背景知识的掌握,需要逻辑的推理、常识的判断等,这些都对多模态理解等提出了突出的科技挑战。来自中国科学院计算技术研究所数字内容合成与伪造检测实验室的曹娟研究员和大家分享了《多模态虚假伪造检测技术体系思考》。曹娟研究员从基于跨度十年的虚假新闻内容大数据分析开始,到多模态融合的虚假伪造检测任务,再到虚假信息的宏观认知和微观解析,全面阐释什么是虚假?如何对复杂的多模态虚假信息检测进行建模?并结合实战,提出了一套数据和知识驱动融合的识别框架和方法。

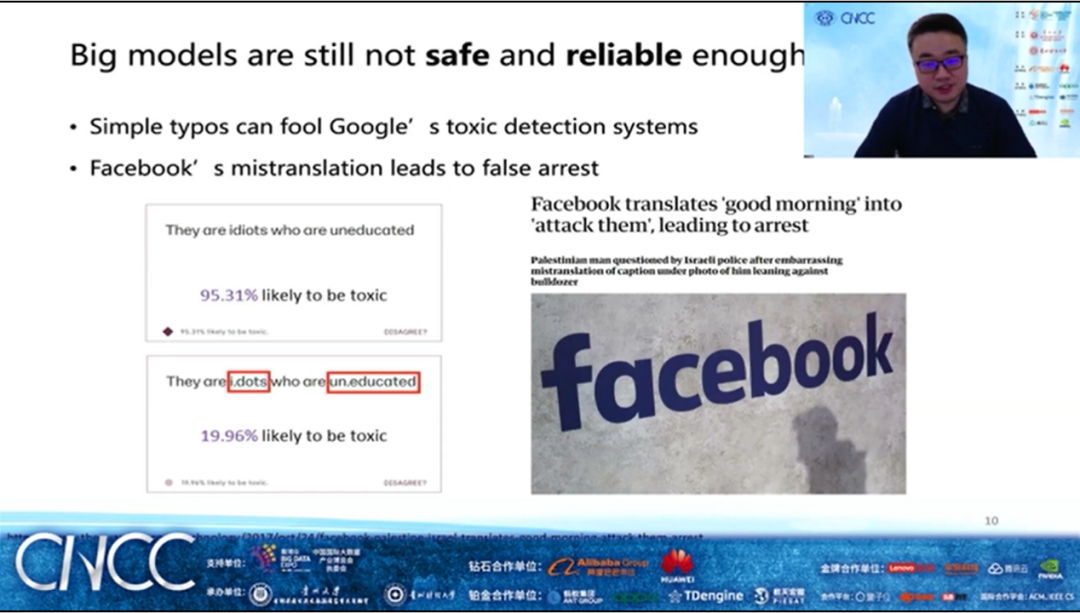
大模型已然成为了虚假信息检测与生成的重要手段,我们是否能够从人工智能伦理的角度出发,对“亦正亦邪”的大模型行为进行规约,把人工智能“关到制度的笼子里”,避免其被滥用造假,是不是可以在内容基础上,更多地关注传播网络中蕴含的丰富信息?来自清华大学的刘知远长聘副教授向大家做了《大模型的安全伦理问题》精彩报告,刘知远教授重点介绍大模型的生成能力与机制,被滥用生成社会媒体虚假信息的风险,并前瞻性分析探讨由此引发的大模型安全伦理问题。
在Panel环节,本次活动还邀请到了阿里安全内容风控算法团队负责人黄龙涛博士一起参加,与会嘉宾围绕为什么虚假信息治理需要交叉学科研究?当下热点的交叉研究方向是什么?针对互联网上海量信息,如何构建多方协同的虚假信息治理体系和生态,形成虚假免疫屏障?在虚假信息检测中的预训练模型方面,针对虚假信息涉及面广,语义丰富导致检测难的问题,预训练大模型中包含丰富的语义及先验知识,对众多下游任务中都有很大的提升,对于虚假信息检测任务,一方面要使大模型具备检测能力,我们需要加入虚假、仇恨等数据;另一方面,这样的大模型又易于被用于生成虚假或仇恨等言论,但去除这些数据又会影响第一点。这个矛盾如何解决?在虚假信息检测中关于知识增强方面,知识能够在虚假识别中发挥作用,使用哪些知识进行虚假信息识别,未来还会有哪些挑战?在虚假信息识别结果的可解释性方面,针对不同场景和不同特点的虚假信息,如何构建合理、公平的可解释性相关评测基准?等问题展开了一场激烈的研讨,同时解答了在线观众提出的问题,嘉宾们精彩观点和观众提问时不时碰撞出的火花,把论坛的氛围带到了高潮。

本次论坛是人工智能网络生态治理的系列论坛之一,为广大科研工作者和学生提供了一个学术交流、思想沟通的平台,吸引了众多观众发表新颖独特的学术见解,促进了不同领域学者之间的互通分享,期待更多的青年、研究者参与到人工智能网络生态治理领域的研究中。






