 返回首页
返回首页

ADL146《大模型自主智能体与群体智能》开始报名
CCF学科前沿讲习班
CCF学科前沿讲习班
CCF Advanced Disciplines Lectures
CCF ADL第146期
主题 大模型自主智能体与群体智能
2024年5月17日-19日 北京
在CCF学科前沿讲习班ADL146期《大模型自主智能体与群体智能》中,我们将深入系统地介绍大模型自主智能体的基础技术及其最新进展,涵盖从单一智能体的基础理论与技术原理,到多智能体之间的分工协作机制;从面向任务的工具学习,到基于多智能体系统的模拟研究,以及相关拓展问题等多个维度。旨在通过深入浅出的讲解,使学员不仅能够掌握大模型自主智能体与群体智能的核心知识和关键技术,还能深刻理解其面临的主要挑战和众多应用场景。我们相信,学员通过本期ADL的学习,将能够大幅拓宽其科研视野,并显著增强在人工智能领域的实践能力。
本期ADL讲习班邀请了7位来自国内外著名高校活跃在前沿领域的专家学者做主题报告。第一天,刘知远、秦禹嘉、林衍凯将分别讲解通用人工智能引言、智能体自主记忆、规划与决策技术、工具学习技术。第二天,钱忱、陈旭将介绍大模型群体智能技术、大模型社会与经济模拟技术。第三天,梁一韬、胡迪将介绍开放域自主智能体、基于自主智能体的机器人技术等课题。通过三天教学,旨在带领学员实现对自主智能体与群体智能从基础技术到前沿动态再到创新应用场景的深入学习与思考。
学术主任:刘知远 副教授 清华大学/林衍凯 准聘助理教授 中国人民大学
主办单位:中国计算机学会
本期ADL主题《大模型自主智能体与群体智能》,由CCF高级会员、清华大学刘知远副教授和中国人民大学林衍凯准聘助理教授担任学术主任,邀请到(按照讲座顺序排序)刘知远(清华大学)、秦禹嘉(清华大学)、林衍凯(中国人民大学)、钱忱(清华大学)、陈旭(中国人民大学)、梁一韬(北京大学)、胡迪(中国人民大学)等七位专家做专题讲座。
活动日程:
2024年5月17日(周五) | |
09:00-09:10 | 开班仪式 |
09:10-09:20 | 全体合影 |
09:20-10:00 | 专题讲座1: 大模型驱动的自主智能体与群体智能:迎接智能的第二次涌现 刘知远,副教授,清华大学 |
10:00-12:00 | 专题讲座2:智能体自主记忆、规划与决策技术 秦禹嘉,博士生,清华大学 |
12:00-13:00 | 午餐 |
13:00-16:00 | 专题讲座3: 大模型工具学习 林衍凯,助理教授,中国人民大学 |
2024年5月18日(周六) | |
09:00-12:00 | 专题讲座4: 大模型群体智能技术 钱忱,助理研究员,清华大学 |
12:00-13:00 | 午餐 |
13:00-16:00 | 专题讲座5: 基于自主智能体的社会与经济模拟 陈旭,副教授,中国人民大学 |
2024年5月19日(周日) | |
09:00-12:00 | 专题讲座6: 开放世界下的通用智能体 梁一韬,助理教授,北京大学 |
12:00-13:00 | 午餐 |
13:00-16:00 | 专题讲座7: 基于自主智能体的机器人技术 胡迪,副教授,中国人民大学 |
特邀讲者(按照讲座顺序排序)
刘知远
副教授 清华大学
讲者简介:刘知远,清华大学计算机系副教授、博士生导师、中国计算机学会高级会员。主要研究方向为自然语言处理、知识图谱和社会计算。2011年获得清华大学博士学位,已在ACL、EMNLP、IJCAI、AAAI等人工智能领域的著名国际期刊和会议发表相关论文100余篇,Google Scholar统计引用超过4.2万次。曾获2020年和2022年教育部自然科学一等奖(第2完成人)、中国中文信息学会钱伟长中文信息处理科学技术奖一等奖(第2完成人)、中国中文信息学会汉王青年创新奖,入选国家青年人才、2020-2022年Elsevier中国高被引学者、《麻省理工科技评论》中国区35岁以下科技创新35人榜单、中国科协青年人才托举工程。
报告题目:大模型驱动的自主智能体与群体智能:迎接智能的第二次涌现
报告摘要:2023年以来ChatGPT引爆了全球对大模型技术与应用的热烈关注,本报告首先简介人工智能的发展历程,阐明大模型技术的历史地位,然后报告介绍大模型的智能涌现等特性,探讨大模型在工具智能、自主智能体、群体智能方面的发展趋势和技术动态,展望智能第二次涌现的图景。
秦禹嘉
博士生 清华大学
讲者简介:秦禹嘉,清华大学电子工程系2016级本科,计算机系2020级博士,导师为刘知远副教授。研究方向为:(1)大模型高效预训练,即使用更少的算力训练效果更强的大模型;(2)大模型高效微调,即微调极少的参数达到全参数微调的性能,节省大量的显存;(3)工具学习,即教会大模型像人类一样灵活使用外部工具,拓展自身能力边界。博士期间发表 15 篇一作/共一 AI 顶会论文(ICLR、NeurIPS、Nature子刊、ACL、NAACL、EMNLP、TMLR、TASLP等)。谷歌学术引用量 1400+,发布多个开源项目(XAgent, ToolBench, BMTools, WebCPM等),GitHub星标累计 20000+。曾获百度奖学金、腾讯犀牛鸟一等奖奖学金、世界人工智能大会优秀青年论文奖、中国算力大会最佳论文等。
报告题目:智能体自主记忆、规划与决策技术
报告摘要:近年来,大模型在自然语言处理、计算机视觉、生物学等诸多领域展现出惊人的应用价值,大模型加持下的智能体能够在理解用户需求的前提下代替用户调用工具、进行多步序列决策从而解决复杂问题。这其中,长期记忆能力、推理规划能力和多步决策能力对智能体的任务执行性能有非常大的影响。在本报告中,我们将首先简要回顾基于大模型的自主智能体的发展脉络,并重点针对上述三项内容的最新前沿研究展开讨论。此外,我们将基于上述讨论,展望未来的智能体技术发展方向。
林衍凯
准聘助理教授 中国人民大学
讲者简介:林衍凯,中国人民大学高瓴人工智能学院准聘助理教授,主要研究方向为预训练模型和大模型智能体,在 CCFA/B 类国际顶级学术会议发表论文 50 余篇, Google Scholar 统计引用(至 2024 年 2 月)达到 11,938 次, H‑index 为 41,2020-2022年连续三年入选爱思唯尔(Elsevier)中国高被引学者。其成果获评教育部自然科学一等奖(第三完成人)、 2022 年世界互联网大会领先科技成果(全球共15项)。在知识表示方面,其TransR论文被 Yoshua Bengio 在其《Deep Learning》教材中列为知识表示代表方法,相关工作成果开源工具包 OpenKE、 OpenNRE 在世界影响力最大的开源平台 Github 上获 7,800 多个星标。在大模型智能体方面,主持发布了世界上第一个大规模工具学习大模型ToolLLM;主持发布了大模型自主智能体系统 XAgent,在开源平台 Github 上获 6,900 多个星标;构建了用于模拟用户行为的多智能体仿真平台RecAgent,是国内外首个用于模拟用户行为的多智能体平台。
报告题目:大模型工具学习
报告摘要:近年来,大模型在自然语言处理、计算机视觉、生物学等诸多领域展现出惊人的应用价值。大模型在大规模预训练中获得的在复杂交互环境中的非凡理解、推理、规划和决策能力,进而展现出在复杂真实场景下调用工具解决复杂任务的巨大潜力。本报告的内容为大模型工具学习,介绍大模型如何能够理解和使用各种工具来完成任务,包括其统一框架、主要挑战、重要工作和未来方向。
钱忱
助理研究员 清华大学
讲者简介:清华大学软件学院博士,目前在清华大学自然语言处理实验室(THUNLP)担任博士后,清华大学水木学者,主要研究方向为预训练模型、自主智能体、群体智能;合作导师为孙茂松和刘知远教授,曾在ACL、SIGIR、AAAI、CIKM等人工智能、信息管理、软件工程等相关的国际学术会议或期刊上以第一作者身份发表论文数篇。在群体智能方面,主导发布了大语言模型驱动的多智能体软件开发框架ChatDev,是国内外第一批实现以任务完成为导向的多智能体系统,其开源系统于2024年3月累计获得超2.2万个星标关注,曾连续多天登顶Github Trending榜单。其背后强大的群体协作模式被谷歌DeepMind大模型产品负责人Bailey和资深数据科学家Sanyam Bhutani等人进行解读,人工智能著名学者Andrew Ng(吴恩达)在红杉美国AI峰会上以ChatDev为例强调了多智能体协作是一种强大的设计模式。
报告题目:大模型群体智能技术
报告摘要:大模型驱动的全流程自动化软件开发框架ChatDev(Chat-powered Software Development)拟作一个由多智能体协作运营的虚拟软件公司,在人类用户指定一个具体的任务需求后,不同角色的智能体将进行交互式协同,以生产一个完整软件(包括源代码、环境依赖说明书、用户手册等)。这一技术为软件开发自动化提供了新的可能性,支持快捷高效且经济实惠的软件制作,未来将有效地将部分人力从传统软件开发的繁重劳动中解放出来。本报告会基于ChatDev的关键思路,围绕大语言模型智能体的构建、协同、演化等方面进行相关技术和实践分享交流。
陈旭
准聘副教授 中国人民大学
讲者简介:陈旭,博士毕业于清华大学,随后进入英国伦敦大学学院(UCL)从事博士后研究,于2020年加入中国人民大学。他的研究方向为大语言模型,因果推断,推荐系统等。曾在TheWebConf、NeurIPS、AIJ、KDD、ICLR等著名国际会议/期刊发表论文80余篇,Google Scholar引用5500余次,入选斯坦福大学全球前2%顶尖科学家榜单。他的研究成果曾荣获CCF自然科学二等奖(排名第二),ACM-北京新星奖(北京市三人),CCF A类会议TheWebConf 2018最佳论文提名奖、CCF B类会议CIKM 2022最佳资源论文Runner Up奖、著名亚洲信息检索会议SIGIR-AP 2023最佳论文提名奖以及著名亚洲信息检索会议AIRS 2017最佳论文奖。他带领团队撰写了国际上第一篇大语言模型智能体综述、构建了首个基于LLM Agent的用户行为模拟环境“RecAgent”等。他主持/参与十余项国家自然科学基金以及企业合作项目,相关成果在多家企业落地,荣获华为“创新先锋总裁奖”, 以及华为优秀校企合作项目等。
报告题目:基于自主智能体的社会与经济模拟
报告摘要:人类行为模拟一直以来是学术界关注的重点,然而传统模拟方法由于难以准确刻画人类复杂决策过程,往往模拟精度和应用范围均较为受限。近年来,大语言模型的发展使人们看到了构建精准类人代理的希望。斯坦福大学的虚拟小镇更是给众多相关从业者带来了巨大的想象空间。本报告将系统讲解过去一年中,科研人员在“基于大语言模型智能体的人类行为模拟”方面做出的种种探索和努力,并分析该领域目前存在的核心问题以及潜在解决方案。
梁一韬
助理教授 北京大学
讲者简介:梁一韬博士,北京大学人工智能研究院助理教授,博导,博雅青年学者。2021年6月于加利福尼亚大学洛杉矶分校获得博士学位,从事神经符号融合的研究,一直致力研究如何将知识注入机器学习中以提高其性能和通用性。曾获得过强化学习顶级会议AAMAS2016最佳论文提名、在ICML19举办的Reinforcement Learning for Real Life Workshop最佳论文及在NeurIPS 2017举办的Learning from Limited Labeled Data(LLD)Workshop次佳论文,在ICML2023举办的TEACH Workshop最佳论文。在学术服务方面,常年担任多个顶级期刊和会议的领域主席(资深审稿人)。
报告题目:开放世界下的通用智能体
报告摘要:随着大型语言模型的出现,关于是否会出现通用智能体的辩论重新兴起。然而,GPT在所涌现的通用能力,在除了文字领域似乎很难再现。在这次分享中,我们将介绍我们组以及其他一些相关的知名研究实验室的各种在使用开放世界环境(例如Minecraft)来开发通用智能体的努力。由于其超高的自由度,传统的多任务数据驱动的方式不可维系(我们无法对上千的任务同时进行大规模训练,过于昂贵)。一个可能的方向是,利用一些通用常识来获得高训练效率和模型泛化性。我会重点介绍如何利用大语言模型来利用环境知识进行具有系统泛化能力的任务拆解,以及如何利用无监督学习获得一个通用的可随提示(prompt)控制(steerable)的通用策略表达,并展现在Minecraft现在最前沿的智能体大概具备什么样的任务完成能力。
胡迪
准聘副教授 中国人民大学
讲者简介:胡迪,现任中国人民大学高瓴人工智能学院准聘副教授,博导,受中国科协青年人才托举工程资助。主要研究方向为机器多模态感知与学习,以主要作者身份在领域顶级国际会议及期刊上发表论文30余篇,如TPAMI、NeurIPS、CVPR、ICCV、ECCV等。代表性工作如视音多模态场景理解算法DMC与场景问答任务MUSIC-AVQA;平衡多模态学习理论,机制与方法;和以运动学为引导的可泛化铰链物体操纵等。攻博期间曾入选 CVPR Doctoral Consortium;荣获2020中国人工智能学会优博奖,2021陕西省优博奖;荣获2022年度吴文俊人工智能优秀青年奖;百度全球顶尖人工智能人才计划等。受邀为多个国际高水平会议及期刊审稿,担任AAAI、IJCAI SPC/Session Chair等,并主办/协办多场国际顶级会议的多模态学习讲习班(Tutorial)。
报告题目:基于自主智能体的机器人技术
报告摘要:近年来,通过海量数据预训练的多模态大模型在复杂交互的环境中展现出的感知、理解、推理、决策的能力,为实现机器人与复杂真实世界交互提供了可靠的基本能力。本报告的内容为基于自主智能体的机器人技术,主要介绍大模型如何支撑机器人在复杂场景下的可泛化操纵,包括语义级别的任务规划、控制级别的策略生成、相关重要工作与未来发展方向。
学术主任
刘知远
副教授 清华大学
简介:刘知远,清华大学计算机系副教授、博士生导师、中国计算机学会高级会员。主要研究方向为自然语言处理、知识图谱和社会计算。2011年获得清华大学博士学位,已在ACL、EMNLP、IJCAI、AAAI等人工智能领域的著名国际期刊和会议发表相关论文100余篇,Google Scholar统计引用超过4.2万次。曾获2020年和2022年教育部自然科学一等奖(第2完成人)、中国中文信息学会钱伟长中文信息处理科学技术奖一等奖(第2完成人)、中国中文信息学会汉王青年创新奖,入选国家青年人才、2020-2022年Elsevier中国高被引学者、《麻省理工科技评论》中国区35岁以下科技创新35人榜单、中国科协青年人才托举工程。
林衍凯
准聘助理教授 中国人民大学
简介:林衍凯,中国人民大学高瓴人工智能学院准聘助理教授,主要研究方向为预训练模型和大模型智能体,在 CCFA/B类国际顶级学术会议发表论文50余篇, Google Scholar 统计引用(至2024年2月)达到11,938次, H‑index 为 41,2020-2022年连续三年入选爱思唯尔(Elsevier)中国高被引学者。其成果获评教育部自然科学一等奖(第三完成人)、 2022 年世界互联网大会领先科技成果(全球共15项)。在知识表示方面,其TransR论文被Yoshua Bengio在其《Deep Learning》教材中列为知识表示代表方法,相关工作成果开源工具包 OpenKE、 OpenNRE 在世界影响力最大的开源平台Github上获 7,800 多个星标。在大模型智能体方面,主持发布了世界上第一个大规模工具学习大模型ToolLLM;主持发布了大模型自主智能体系统 XAgent,在开源平台 Github 上获 6,900多个星标;构建了用于模拟用户行为的多智能体仿真平台RecAgent,是国内外首个用于模拟用户行为的多智能体平台。
时间:2024年5月17日-19日
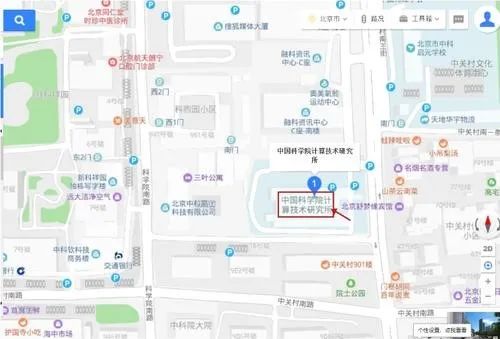
地址:北京•中科院计算所一层报告厅(北京市海淀区中关村科学院南路6号)
报名须知:
1、报名费:CCF会员2800元,非会员3600元。食宿交通(费用)自理。根据交费先后顺序,会员优先的原则录取,额满为止。应部分学员的要求,本期ADL线上同步举办,线上线下报名注册费用相同。线上会议室号和密码将在会前1天通过邮件发送。
2、报名截止日期:2024年5月15日。报名请预留不会拦截外部邮件的邮箱,如qq邮箱。会前1天将通过邮件发送会议注意事项和微信群二维码。
3、咨询邮箱 : adl@ccf.org.cn
缴费方式:
在报名系统中在线缴费或者通过银行转账:
银行转账(支持网银、支付宝):
开户行:招商银行北京海淀支行
户名:中国计算机学会
账号:110943026510701
请务必注明:ADL146+姓名
报名缴费后,报名系统中显示缴费完成,即为报名成功,不再另行通知。
报名方式:
请选择以下两种方式之一报名:
1、扫描(识别)以下二维码报名:
2、点击报名链接报名:
https://conf.ccf.org.cn/ADL146
【相关阅读】





