 返回首页
返回首页

“善解人意”的机器在哪里?——自然语言理解的发展与挑战 | CNCC技术论坛
本论坛将于CNCC第一天(10月22日)下午在杭州分会场举行,共邀学界资深研究专家探讨面向人工智能时代的自然语言理解发展与挑战。
CNCC将于10月22-24日召开。今年CNCC将以北京作为主会场、沈阳、杭州、济南设立分会场并在线上同步直播,各个分会场技术论坛也是精彩纷呈,其中10月22日下午在杭州分会场-杭州市未来科技城学术交流中心:梦想小镇2号会议厅(21号楼)举行的自然语言理解的发展与挑战技术论坛就十分精彩。届时将邀请学界资深研究专家探讨面向人工智能时代的自然语言理解发展与挑战。
自然语言理解被誉为人工智能皇冠上的明珠。虽然相关研究此起彼伏,但是迄今为止,能够理解人类自然语言的计算机还远远无法达到人类需求。
语义理解一直被认为是通向自然语言理解的必由之路,人们不禁要问:
语义理解的本质是什么?
实现自然语言理解的关键技术路径是什么?
如同人类学习一样,机器阅读是否构成语言理解的重要手段呢?
此外,情绪是人类区别机器的重要特征,冰冷的机器能够读懂文本语言所蕴含的情绪吗?
本论坛邀请学术界资深研究专家探讨面向人工智能时代的自然语言理解发展与挑战。一方面,从句子、篇章等多层次分析自然语言理解基础研究的发展现状,另一方面从机器阅读理解、文本情绪识别等方面探讨存在的问题挑战。

论坛主席

苏州大学
周国栋
教授,博导,苏州大学自然语言处理实验室主任。研究方向:自然语言理解、信息抽取、自然语言认知等。
近5年,发表SCI期刊、CCF A/B类国际会议论文100多篇,主持NSFC项目4个(包括重点项目2个) 。据Google Scholar统计,论文引用近9000次。曾担任国际自然语言处理领域顶级SCI期刊Computational Linguistics编委,目前担任ACM TALLIP副主编、《软件学报》责任编委、中国计算机学会自然语言处理专委会主任、中国计算机学会理事、中国人工智能学会自然语言理解专委会副主任、中国人工智能学会常务理事、中国语文现代化学会语言现代化与智能化研究会副理事长。

苏州科技大学
奚雪峰
奚雪峰,博士,副教授,硕导,现任省市共建苏州智慧城市研究院副院长,苏州科技大学智能控制与信息处理研究所副所长,苏州市虚拟现实智能交互及应用技术重点实验室执行负责人,2019江苏省“六大人才高峰”高层次人才。2000年8月毕业于江苏大学获得学士学位;2004年10月毕业于东南大学获得硕士学位;2017年12月毕业于苏州大学获得博士学位;2017年12月至2018年12月为美国普渡大学访问学者。长期从事自然语言处理、数据挖掘与机器学习、软件工程等领域研究工作。主持或参与国家863项目、国家自然科学基金、省部级项目十余项。近年来在《计算机学报》《自动化学报》《ACM Transactions on Asian and Low-Resource Language Information Processing》《IEEE Access》、NLPCC等国内外期刊及会议发表学术论文20多篇;授权发明专利3项。荣获2017年度江苏省科技进步三等奖、2016年度江苏省教学成果二等奖各1项。
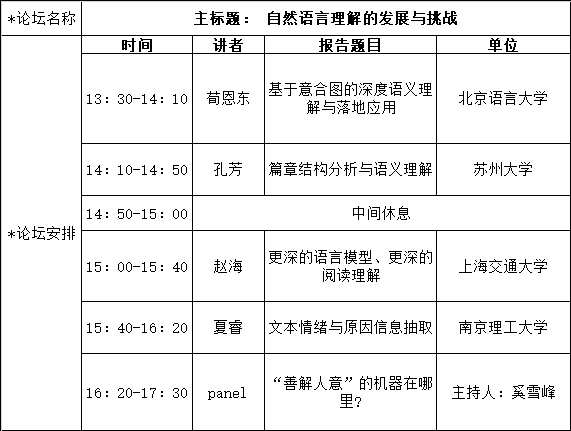
日程安排
讲者简介

北京语言大学
荀恩东
报告一题目:基于意合图的深度语义理解与落地应用
报告摘要:语义理解是语言智能核心研究工作,深度学习处理深度语义分析任务面临瓶颈。如何表示语义、构建语义分析结构和落地应用,是语义理解的主要内容。本研究在组块依存分析基础上,通过符号计算得到汉语句子的语义分析结构,即采用意合图,本报告也讨论利用意合图的命题结构和情态解决实际问题。
报告人简介:荀恩东,教授,博士生导师,北京语言大学语言智能研究院院长,信息科学学院院长,主要从事自然语言语言处理、智能语言学习技术研究和开发工作。目前研究兴趣为汉语句法语义分析。

苏州大学
孔芳
报告二题目:篇章结构分析与语义理解
演讲摘要:在自然语言处理领域,随着句子级研究的日趋成熟,篇章级的研究陆续展开。篇章结构分析和语义理解是一个基础性的研究工作,本报告将从理论体系,到资源建设,到可计算模型,再到上层应用的支撑等多个不同层次介绍中英文篇章结构分析和语义理解相关研究的现状和未来。
报告人简介:孔芳,博士,苏州大学计算机科学与技术学院教授、博士生导师。主要研究领域包括自然语言理解和信息抽取,发表CCF A/B类会议和期刊论文20多篇,主持NSFC项目4个,均与篇章结构分析与语义理解相关。

上海交通大学
赵海
报告三题目:更深的语言模型、更深的阅读理解
演讲摘要:语言模型在早期的统计自然语言处理上曾发挥核心作用,作为核心组件广泛用于语音识别和统计机器翻译。深度学习引入自然语言处理以后,基于低维分布式向量表示的词嵌入大行其道,也取得了显著成果。在2017年以后,以ELMo和BERT为代表的上下文依赖语言模型快速崛起,它继承了语言模型的训练方式,同时具有整句级的编码和词嵌入表示形式。由于对于算力要求较高,这类模型提出了新的预训练-微调的工作方式,因此特别称之为预训练语言模型。各类预训练语言模型已在包括各类语言结构分析(如句法、语义分析)以及机器翻译、机器阅读理解等任务上的巨大性能提升。其中,机器阅读理解是深度学习下的自然语言理解领域在最近几年才引入的新型任务,它已经被证明特别依赖于有效的编码器和语言表示。这个报告中我们将探讨语言模型、表示对于机器阅读理解的技术性影响,包括技术演化的时间线、现状和挑战,特别是最近一年来最新进展和一些个人新的思考。
报告人简介:赵海,博士,上海交通大学计算机科学与工程系教授、博士生导师。研究领域包括自然语言处理、自然语言理解和深度学习。发表论文130篇。Google学术引用3,400余次。ACM专业会员,中国计算机学会自然语言处理专委会委员,上海市计算机学会人工智能专委副主任,2014起PACLIC指导委员会委员。ACL-2017程序委员会Parsing领域主席,ACL-2018、2019形态和分词领域(高级)主席。语义分析CoNLL评测2009,2019第一名,机器阅读理解排行榜RACE、SQuAD2.0第一名。

南京理工大学
夏睿
报告四题目:文本情绪与原因信息抽取
演讲摘要:文本作为人类表达情感和情绪的重要途径,文本情绪分析是人工智能、自然语言处理和情感计算研究的重要组成部分。当前,有两个主要的情绪分析任务:一是情绪识别,其目标是从人类心理学的角度预测文本中人们表达的情绪(如喜怒哀乐);另一个是情绪原因抽取,其目标是抽取文本中某些情绪表达背后的潜在原因。学术界目前采用了包括规则方法、传统机器学习方法和深度神经网络在内的技术来解决这些任务。针对当前研究中存在的问题,我们提出了两种情绪原因抽取深度神经网络模型,在此基础上提出一项新的任务——情绪-原因配对抽取(ECPE),并分别提出两步法及联合框架来解决此任务,旨在以成对的方式联合抽取文档中的情绪及其对应的原因,探索自然语言中情绪和原因的因果关系及其表达规律。
报告人简介:夏睿,博士,南京理工大学计算机学院教授、博导,从事自然语言处理、文本数据挖掘方向的研究,在国内外重要期刊和会议发表/录用论文50余篇、出版学术专著1部。担任人工智能与自然语言处理领域多个国际顶级会议的领域主席、高级程序委员会委员。2016年获得首届江苏省优青项目资助,2017年入选南京理工大学青年拔尖人才选聘计划并破格晋升为教授,2019年获得江苏省六大人才高峰项目资助,2019年获得江苏省计算机学会青年科技奖,2019年获得第57届国际计算语言学年会ACL杰出论文奖,2020年获得江苏省杰青项目资助。
CCF推荐
【精品文章】


CCF颁奖典礼限量门票开售





