
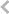







引导发言环节
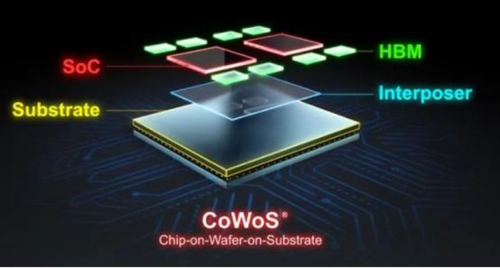
极致能效的专用架构结合可编程性的通用处理器,通过先进封装与系统级互连的AI芯片,将在数据中心大爆发。
数据、算力和算法驱动着人工智能发展的新一轮浪潮。其中,算力是重要的基石。为满足大型模拟计算、科学计算、未来5G技术带来的新场景、新变化,全球算力的需求自2012年起每3.5个月就翻一倍,远远超过了摩尔定律的发展速度。传统计算技术体系困局逐步显现,亟需计算系统架构的革新。

算力需求发展趋势
在引导发言环节,壁仞科技联合创始人焦国方博士介绍了以创新性垂直整合的系统架构,实现远超当前水平的能效提升。他认为,当前智能计算技术的破局应从多个层次进行垂直发展。一是发展更加并行化、更加专用化的芯片架构;二是异构芯片互联封装的高级封装技术(chiplet)。除此之外,利用SmartNIC、DPU等对数据中心的加速,以及创新的软硬件一体化架构也都是实现未来计算需求的关键技术。
燧原科技首席芯片架构师刘彦先生引导发言的题目是“More than Moore,数据中心AI算力架构的新趋势”。针对如何突破摩尔定律,刘彦指出在数据中心中显现出几个显著的趋势:更加专用的计算架构,以英伟达当前的产品结构为例,将数据中心GPU与传统图像计算GPU产品线分离;另外,高级封装(Advanced Package)作为降低芯片研发成本的关键技术,是目前公认的非常有潜力的发展方向;最后,未来的数据中心的架构趋势是资源池化,打破传统的以CPU为中心通过网络互联的模式。刘彦先生在发言中提供了他心目中的未来智能计算发展的关键词:更高维的张量、稀疏性以及空间。
就智能计算领域的需求发展,专用化的计算架构与高级封装技术成为焦国方博士与刘彦先生共同认可的关键技术。
高级封装技术:衬底上晶圆级芯片封装
新一代计算架构:领域专用架构(Domain Specific Architecture, DSA)
地平线BPU算法负责人罗恒先生的引导发言是“如何评估AI芯片的真实性能?”。罗恒先生的发言体现了他对专用AI芯片的认可。罗恒先生指出反映AI芯片真实性能的,除了算力,还应包括利用率、精度、计算效率等。因此,如不能以实际应用场景为基础,对AI芯片进行专门的优化,则会导致芯片真实性能降低。就真实性能的提升,领域专用架构的优势显而易见。
就提高领域专用架构的通用性,焦国方博士也提出了他的看法:尽管DSA具有较高的性价比和能效比,但由于其应用面窄、生态弱的问题,难以满足实际场景中计算的多样性。针对DSA的生态建设与适配性,需要其运算部件和流水线具备可编程能力。另外,DSA与通用GPU(General Purpose GPU, GPGPU)所组成的异构计算系统,能在保证通用性的同时,提供高性价比与高能效比。焦博士认为DSA与GPGPU组成的异构计算系统可能是未来比较长期的发展态势。

AI计算架构性能、通用性比价
更远的未来?彻底颠覆传统的类脑计算芯片
近年来,受神经启发式的类脑计算芯片也取得了举世瞩目的进展。以IBM研发的TrueNorth为典型的类脑计算芯片,由于其彻底颠覆传统冯氏结构计算机的架构设计,成为目前AI芯片领域最前沿的发展方向。在更远的未来,类脑计算芯片是否可能取代如今风头正茂的GPGPU以及蓄势待发的DSA,成为最主流的计算架构呢?
来自上海新氦类脑智能科技有限公司的江伟杰先生为大家介绍了类脑芯片的行业趋势。江伟杰先生提出,类脑芯片与其它芯片有极大的不同:大脑的信号传递速度远低于电脑,但平均每个神经元与七千多个神经元连接,其扇出量远大于目前硅基结构晶体管,保证了极强的并行运算能力。类脑芯片利用脉冲来实现并行运算。因此江先生认为,类脑芯片发展的关键技术包括脉冲神经网络、新兴器件(光学器件)、存内计算以及模拟计算。就类脑芯片的应用来说,传统机器学习利用基于大量数据的归纳法,而类脑计算则利用推理法,适合小样本甚至无样本的任务。在现实中,小样本的场景远大于大量样本的场景。因此,类脑计算芯片在未来必将有巨大的应用前景。
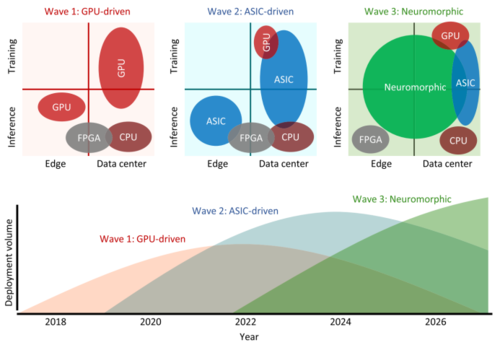
AI芯片架构未来发展态势
专用还是通用?开源还是闭源?AI芯片的发展之路









思辨讨论环节
在思辨讨论环节,我们就AI芯片未来发展上的重要分歧展开讨论。我们还特别邀请了复旦大学的陈迟晓博士、来自上海算力云人工智能科技有限公司的赵文科先生和来自上海阵量智能科技有限公司的王勇先生共同参与思辨。
第一个问题我们就AI芯片架构未来的发展展开讨论,探寻GPGPU、DSA以及类脑芯片未来会是一方独大还是百花齐放。
就AI芯片的灵活性、通用性、可移植性与以需求为导向的专用设计之间的对立,思辨嘉宾展开了激烈的讨论。来自听众席的黄朝波先生认为,以数据中心为主要应用场景的AI芯片,灵活性与通用性是必须具备的能力。定制化的芯片导致灵活性的降低,满足不了用户应用场景的急速迭代;同时,智能计算只是数据中心需要解决的一部分问题,为满足数据中心的多任务需求,需要有统一标准并且可实现应用编程的硬件。与之相反的,罗恒先生则表示AI芯片架构设计应该是需求驱动的,通用性与可编程性不应作为AI芯片架构的发展方向。针对黄朝波先生提出的观点,罗恒先生进行了一一的反驳:在AI芯片设计阶段进行完善的、具有前瞻性的需求分析可以很大程度的满足应用场景的快速迭代,例如Google TPU的设计是基于大量用户应用模型的综合分析,并且时至今日依然能满足用户需求;而针对数据中心的多任务需求,罗恒先生认为目前神经网络在架构不变的情况下,通过输入、输出的定义,已然能实现众多应用任务。因此,他认为未来只要掌握数据的公司都会自己做专用芯片,根据算法定制化芯片,可以降低成本。
然而,为满足AI芯片通用性与性能的折中,更多的嘉宾则认为多种架构的共存以及异构可能才是未来的主流趋势。王勇先生认为对AI芯片架构的讨论应该将推理和训练区分开,对于训练,他认为GPGPU架构具有比较优势;对于推理,他表示跟应用和模型强相关,DSA可能是发展趋势。刘彦先生则表示对AI芯片架构的讨论,需要建立在对应用场景的完整理解上,数据中心是一个场景,如何处理大量稀疏化、非结构化的数据是一个重要的问题,端侧是另外的场景,未来会出现通用芯片和专用芯片互补的情况。第二个问题我们讨论了AI芯片生态的打造,分析AI芯片是否需要利用开源去扩宽生态、谋求生存。
来自听众席的黄朝波也发表了自己的观点“在小系统上生态不重要,在大系统上生态非常重要。边缘侧可以定制。在大系统上,大家最好是遵循一套标准,生态一定是非常重要的。”他还提出“开源、闭源都不是百分百的,而是在某一个层次上的开和闭。CUDA是在application层上的开源,RISC-V是在指令集层上的开源,定制AI加速器在宏指令的层上的开源。”
刘彦先生表示英伟达公司的软件生态中有几十万的开发者,是其十几年来积累的财富。在游戏和图形方向上做到CUDA这样的生态是不太现实的,但是AI是一个新的突破口,目前还没有形成垄断。破局的第一步是框架的开源和(编程开发的)支持,第二步是对硬件体系架构抽象的编程接口开源。
陈迟晓博士认为目前讨论AI芯片的开源可能还为时过早,目前开源还只适合于RISC-V这样的指令集架构。罗恒先生显然对此观点表示了一定程度的赞同,他认为对于求生存的小公司而言,做生态很难。
看来对于AI芯片的生态打造将会是一个长期的过程,同时也会是未来的机遇。
紧接着AI芯片架构及开闭源问题,我们讨论了开源指令集架构RISC-V是否会在未来的AI芯片及计算机架构发展中大放异彩。
段圣宇博士的观点是RISC-V在CPU设计上已成为除了x86和Arm外的第三大指令集架构,其思想和领域专用架构非常相似的,两者实际上在解决同一件事情。随着未来领域专用架构逐渐成为主流,可定制化设计的RISC-V指令集也将随之发挥极大的作用。
陈迟晓对以上观点进行了补充,他表示没有RISC-V,就没有软件生态可言。RISC-V是实现AI加速器最经济的办法。同时,RISC-V的开源也促使了更多指令集的开源。
相反地,王勇认为“近几年软件定义硬件的概念大热,未来芯片公司出路在哪里?掌握数据的大公司都开始自己做芯片,自己定义指令集,形成闭环了。这是和RISC-V相冲突的。未来开放指令集架构的路不好走。” 赵文科则认为从市场角度来看,还是英伟达的芯片占主导。RISC-V在研究层面可以进一步去推广,但在市场层面还没有看到用例。
嘉宾们对RISC-V开源指令集的讨论反映了科研领域与产业市场之间的碰撞。RISC-V及其它指令集的开源无疑在芯片研究领域推动了更多尝试的可能;然而,就芯片产业及市场而言,我们可能需要更加成熟、稳定的系统架构,RISC-V作为强定制化的新兴架构很显然难以满足。
总结:摩尔定律必将终结,不管是开源还是闭源,软件定义硬件,有应用场景才有价值。AI芯片变革性的改革,需要大家共同的添砖加瓦。
本次论坛活动在大家的热烈讨论中圆满结束。
 参会者合影
参会者合影

















