


深度解析金融多元场景企业级知识图谱实践
多年来,图谱技术有了日新月异的发展,金融行业也逐步成为图谱落地的重要战场。在CCFTF76《金融知识图谱构建与应用:进展与展望》中,来自蚂蚁集团知识图谱团队的梁磊,为大家带来了分享《金融多元场景企业级知识图谱实践》,此次分享主要分为四个部分:蚂蚁金融知识图谱的总体介绍、两个知识图谱应用案例、知识图谱的总体架构以及它的发展与展望,让我们一起回顾精彩内容。

梁磊 蚂蚁集团,技术总监
个人主要技术方向为知识图谱、搜索推荐引擎及AI工程等。先后在百度、高德担任搜索引擎核心研发工作,2010年硕士毕业于电子科大,2016年加入蚂蚁并于2018年主导蚂蚁知识图谱建设,基于蚂蚁多样性的金融业务场景构建了企业级知识图谱架构,目前也在主导IEEE 2807.2金融知识图谱标准化工作。
蚂蚁知识图谱简介
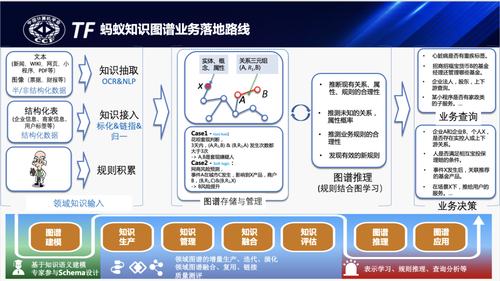
梁磊首先提到蚂蚁知识图谱的业务落地路线,它和大多数领域图谱的落地路线是基本一致的。总体流程上分为四部分,首先是知识建模,需要领域专家参与并基于图谱本体模型完成领域图谱的建模,然后使用图谱的构建工具将业务数据构建为强schema约束的领域图谱表达,图谱构建完成后再结合业务场景来构建具体的推理能力,最后进行业务决策与应用。金融场景各领域知识图谱构建一般包括业务知识构建、专家经验构建两部分:
•业务知识:主要包括业务长期积累的结构化数据,也包括相关非结构化、半结构化的文档/图片等数据,通过知识生产pipeline链路实现结构化、标准化、语义化,通过实体、概念、属性、关系等的更新写入图谱。
•专家经验:主要指业务决策所依赖的经验沉淀,如重疾判定、风险事件影响面的定义、疑似套现行为判定等,相对于通用知识图谱,金融知识图谱也更看重专家经验的积累和构建,构建好的图谱规则往往采用KGDSL进行形式化描述和存储。
关于专家规则定义举两个简单的例子,第一个识别套现嫌疑人,若A用户、B商户在短时间内的多次往返交易并超过一定金额往往被认定为潜在套现行为相关用户 ,第二个是关于风险事件传播的,比如C城市的猪肉价格上涨会直接波及到相关的商贩、养殖场、饲料供应商等,通过事件-城市-产业链的传导能定义出事件可能的影响范围。
领域图谱构建完成以后,就进入到图谱推理应用环节,图谱推理一般包括规则推理和表示学习。相对于RDF/OWL规则推理体系,金融场景规则推理一方面要求能准确定义并匹配风险传导结构,另一方面也要求在匹配过程具备一定统计聚合的风险浓度判断。图谱表示学习则结合图谱语义结构、专家规则约束做了更多增强,主要任务包括实体关系预测、属性分类等,也可以通过学习实体、关系的embedding表征输出给下游应用。下游的业务应用可以直接基于图谱数据提供知识服务,也可以基于规则KGDSL、图谱表征提供实时或离线的推理服务能力,无论是风控类还是营销类业务都可以接入图谱推理的能力。
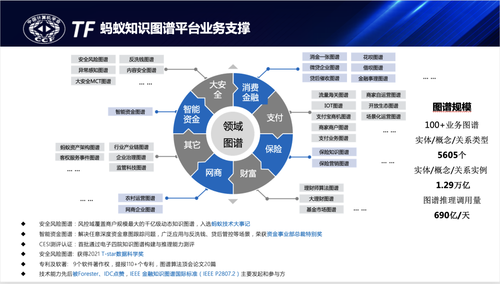
蚂蚁知识图谱从2018年开始建设,通过平台化的方式支持包括支付、安全、网商、保险、财富、资金等的领域图谱建设,蚂蚁有多元化的图谱应用场景,基于不同场景差异化的需求沉淀了可快速孵化领域图谱解决方案的蚂蚁知识图谱平台。通过对业务共性的抽象沉淀知识图谱基础引擎、开放平台SDK及基础算法能力,在后续的图谱平台架构章节会展开介绍。经过过去四年多的积累和打磨,蚂蚁知识图谱累计沉淀领域实体、关系5000多个,各领域图谱累计实体、关系规模约1.29万亿规模,图谱推理日调用量690亿+,知识服务日调用量也超千亿,通过这几年的深耕打磨,公司内外也获得了一些认可和奖励,发表多项顶会论文及专利,目前蚂蚁知识图谱也在和高校、机构合作建设金融知识图谱国际标准IEEE2807.2。
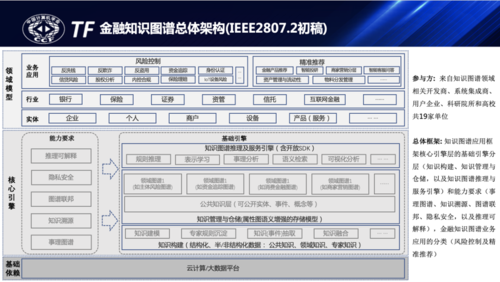
上图是前面提到的IEEE2807.2金融知识图谱标准的总体框架,经过和合作机构、院校的多轮讨论形成上图的初步框架,和蚂蚁知识图谱架构的建设基本一致。它在整体框架上分为三层,基础依赖层主要是大数据基础环境,核心引擎层包括基础引擎和能力要求两部分,基础引擎和其他领域知识图谱是基本一致的,包括图谱构建、知识管理、推理应用等,这里不再赘述。值得一提的是金融图谱不同场景间也会有较多可复用的知识,如企业、自然人、商户、产品等实体及关系,在知识管理中增加了公共知识管理的能力,方便各场景之间公共图谱的共享和连接,能力要求中体现了金融知识图谱特色或更加看重的一些能力,目前主要定义了五部分:
•隐私安全:金融知识图谱中涉及的用户、商户、企业等实体都有强监管要求,首先要满隐私保护、数据安全的要求,在保障隐私安全的情况下,实现知识的沉淀与管理有效互联。这些是根本性的问题,对AI的影响也会变得越来越重要,也决定了未来整个数字经济的走势,金融知识图谱的发展也必须是在确保安全的前提下。
•推理可解释:现在主要的AI模型基本都是黑盒模型,尤其是深度学习模型,用户很难理解中间具体的决策过程,但金融场景的应用往往对推理决策结果的可解释性有较高的要求,如保险拒赔、拒保,商户涉嫌欺诈判定、用户真实性等,业界在推理可解释上也有较多探索,知识图谱天然具备深度互联、语义化的优势,推理可解释也是对其的必然要求。
•图谱联邦:又可称之为联邦图谱,随着隐私安全的要求越来越高,如何在满足隐私安全的情况下,实现跨主体、跨机构的图谱连接与知识共享,是金融知识图谱必须解决的技术课题。隐私 + 图谱也越来越成为业界的探索方向,在金融隐私合规的大趋势下,既存在更大的技术挑战,又是基础的能力要求。
•知识溯源:在企业级的知识图谱实践中,通过融合不同的领域图谱实现不同实体之间的连接、实体的消歧融合,以融合后的图谱支撑下游的推理应用,但实体归一后如何溯源不同源实体的价值贡献是一个较大的难题,随着知识要素的市场化,确权和量化各类来源的贡献和价值也是比较基础的能力要求。
•事理图谱:金融场景往往是和风险相关的,高效捕获并沉淀外部风险事件并快速评估对关联企业、产业、服务等的影响,能极大提升风险感知水平,降低客户风险,提升用户体验。金融知识图谱须具备理解外部风险事件,并将外部风险事件标准化建模、结构化沉淀,做到风险事件的高效感知、沉淀并联动内部图谱实现实时的风险预测。
领域模型层面从促增长和控风险两个层面对业务分类划分,一手控制客户风险水平、一手拉新促活促业务增长,两手抓两手平衡,主要应用场景也覆盖金融行业的方方面面,上图也示例了一些典型的公共实体。金融知识图谱在业务应用中是偏中后台通用能力,强业务属性的场景、流量、规范等服务及决策不在金融图谱的规范范畴,但需具备和业务系统联动数据对齐的能力。目前IEEE2807.2已完成第六轮电话讨论,也欢迎大家一起共建,完善和丰富金融知识图谱的整体框架、案例,推进金融知识图谱的标准化和应用能力建设。
知识图谱应用案例
对蚂蚁知识图谱及IEEE 2807.2金融知识图谱总体框架做了简单介绍后,梁磊结合两个案例介绍蚂蚁知识图谱的业务落地,首先是通过构建商家知识图谱支持业务增长。
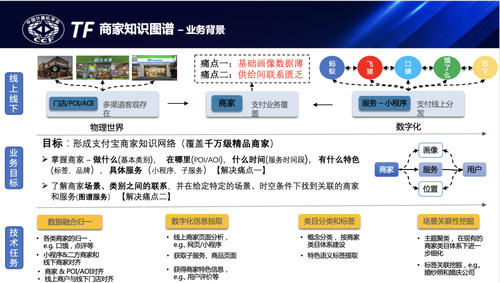
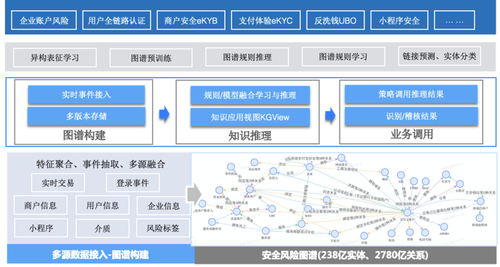
蚂蚁商家业务主要分为线上和线下两部分,线上主要包括收款、服务、小程序等,每个商家都有至少一个收款二维码,也会开通小程序服务或接入飞猪、饿了么等用于线上服务运营,线下主要包括具体的经营门店、经营商品等。在实际业务应用遇到的问题主要包括几类:第一,线上/线下缺少有效的联动,线上收款码、小程序与线下门店、POI等不能有效关联,一码多店、一人多码、游商等问题又把关联变得更加复杂;第二,线上商家服务信息也有较多的来源,飞猪、饿了么、蚂蚁等口径、结构和质量也都有较大差异,需要实现多源门店的消歧和归一;第三,通过小程序、服务等的页面及内容理解抽取商家的经营属性和经营内容。商家图谱的核心目标是通过实现多源服务的消歧归一、线上线下的有效挂载来解决商家基础画像薄弱、实体间关联匮乏的问题,构建精品商家知识网络,通过图谱理解商家是做什么的,经营地在哪里,在什么时间段以及有哪些特色的服务,具体的服务内容是什么,目标是实现对商家的经营能力和经营范围的清晰洞察,也给商家提供相对精准的运营支撑和活动引流。为此,结合商家、位置、服务、用户等核心实体构建了商家知识图谱,它的总体架构如下图所示:
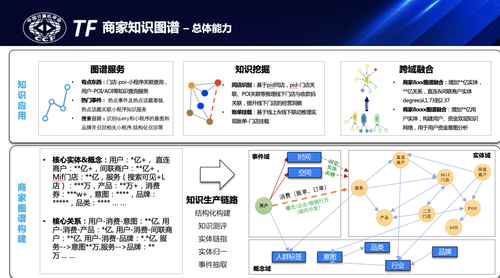
通过知识生产框架构建基于实体、事件、概念模型的商家知识图谱领域模型,并基于商家图谱提供知识服务、推理挖掘、跨域图谱融合等业务应用,通过图谱服务提供语义召回、知识查询等在线服务能力,通过图谱推理挖掘商户同人、同店关系,预测线上线下商户的联动,通过用户、服务/offer的语义关联,在搜索场景通过语义检索召回及推荐场景通过图谱用户、item的联合表征学习,都取得了较好的效果提升。商家图谱也作为基础公共图谱也支撑了跨业务的融合应用,下面也结合知识融合介绍一个简单案例。
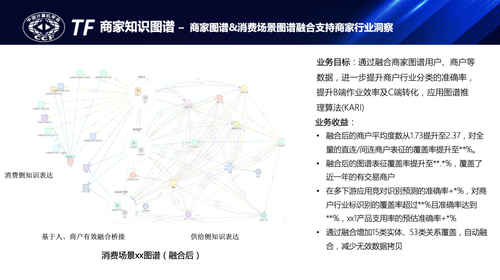
蚂蚁不同的业务场景都和商家有一些关联,上图示意了某消费场景的图谱应用,业务对用户在本场景的消费能力、消费偏好及相关商户的经营能力、经营画像等都有较深刻的洞察,业务面临的难题是如何更全面的理解B端商户及C端用户偏好,需要补全更多的基础信息。面对这些问题,业务的一般做法是从数仓中找相关基础画像源表并与本域的用户、商户表口径对齐后,通过多表join、二次加工在本域再构建一套基础信息表,但这样既增加业务成本拉长了项目周期,又有较多数据重复拷贝,也容易造成潜在的不一致。
蚂蚁知识图谱平台通过连接即可用的跨图谱融合能力为业务提供了第二种选择,消费场景知识图谱与商家知识图谱通过用户、直连商户、间连商户等几个hub实体的跨图谱融合构建两个图谱之间的连接,在无需数据拷贝的情况下做到连接即可用,既减少了领域图谱的构建成本,又丰富了该消费场景图谱的实体关系表达。融合后消费场景图谱商户实体平均degree从1.73提升到了2.37,同时基于图谱的推理应用在多下游任务中也取得了不错的效果,如竞对识别、商户行业分类、产品支用率等,有效提升了商家运营效率、线下小二的作业效率,也提升了消费产品C端的分发效率和转化率。
第二个案例是安全风险图谱,前面的案例是促增长,本案例则是控风险,首先举例典型的风险问题。
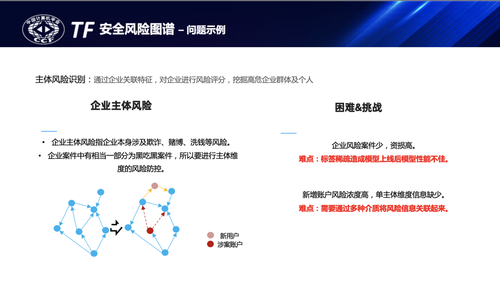
企业是安全风险防控的核心主体,在企业账户风控场景中,存在一定量的主体风险账户,这些账户主要从事如赌博、欺诈、洗钱、禁售等不法行为,因此对企业主体做风险防控尤为重要。而这些企业账户又普遍存在真实性问题,新注册企业、沉睡户复活等需求,而对这些信息稀薄的长尾客户做风险防控又是必须解决的核心问题,直接通过企业画像建模实现风险分类往往因为标签稀疏而导致模型效果不佳,而存在主体风险的企业很多时候在不同维度上也存在一定关联。如:名称相似、注册地相似、交易往来、介质相同等。因此期望通过图谱的标签语义、介质属性等的关联实现企业主体之间的关联扩展,借助图谱推理模型提升风险分类的准确率和性能。
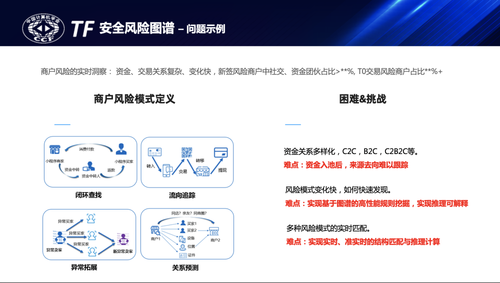
另外,商户维度的风险防控往往和资金交易相关,比如实时套现、诈骗资金分赃等往往在几分钟或数小时内完成,且呈现严密的组织性、团伙性。在这些风险案件中社交关联、团伙作案比例很高,实时交易的占比也非常高,实时风险防控难度很大,主要表现为几个方面:第一,商户风险防控是实时动态的攻防过程,风险模式pattern复杂,如左上图所示,风险团伙极尽可能的利用风险防控的漏洞,通过更多的账户、更多中间人、更小涉案金额等实现资金的混淆,如何更快的识别和发现这些风险模式是业务人员面临的难题;第二,金融产品交易链路资金混淆,资金进入到不同的金融产品后很难区分每一笔交易的来源和去向,也难以区分正常交易和涉案交易,包括相关的金额;第三,是图谱推理的计算瓶颈,千亿规模图谱下实时多跳的子图匹配及表示学习也面临规模和实效性的问题;第四,风险场景决策结果的可解释性要求,需要提供推理结果的可解释要素。因此解决方案是在安全风险图谱中结合子图实时匹配推理、规则挖掘、资金来源去向追踪、可解释的图谱推理等多个维度建设商户风险防控能力。
下图是安全风险图谱的总体架构示意图,通过商户、用户、企业等核心实体的构建,设备介质、属性画像等的关联建模构建安全风险图谱底盘。
目前安全风险图谱的规模已超过3000亿,也是覆盖商户、用户规模最大的动态多版本风险图谱,应用在商户风险防控、用户/企业主体账户风险识别、反洗钱UBO尽调分析等eKYB、eKYC事前/事中/事后的风险防控,推理能力上也较多应用了图谱表征学习、规则推理、规则&模型融合的推理等,因安全场景风险模式复杂,业务有较多的专家经验沉淀,安全风险图谱是图谱规则推理应用较为广泛的场景之一。
下面是结合UBO最终受益人四要素信息补全的安全风险图谱应用案例。
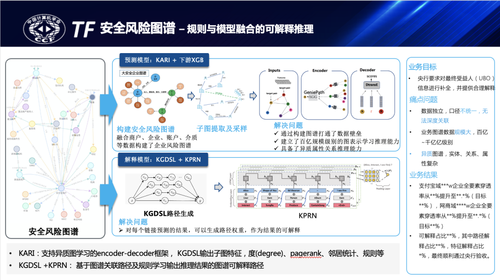
蚂蚁作为反洗钱的义务机构需要识别企业受益所有人的信息,UBO即Ultimate Beneficial Owner,它的定义是直接或者间接拥有超过25%公司股权或者表决权的自然人。这不仅是KYC工作的重要一环,也可以帮助业务更好地识别企业风险。反洗钱UBO信息补全任务具体包括:补全UBO的姓名、地址、证件号码、证件有效期四要素。首先通过图谱实体映射与融合来构建企业风险图谱,通过实体映射与融合技术将外部企业工商信息、董监高、法人等信息与内部企业、商户、介质数据进行融合,并将外部的自然人信息映射到注册账户从而构建企业风险图谱。然后是通过实控人计算来粗召回UBO候选集,基于企业公开数据可以获得企业股东的姓名和直接持股比例,再结合股权穿透算法和路径搜索算法计算出企业-自然人之间的所有持股路径,进而按照股权穿透持股比例识别出企业UBO的姓名,然后将同姓名的自然人作为该企业的UBO候选集。第三步是链接预测,采用图谱表示学习算法KARI,并将部分已知的企业-UBO关系对作为标签进行有监督训练,然后采用训练好的模型对所有企业-UBO候选人关系对进行打分,并融入下游XGB模型中结合企业经营特征和候选人画像特征进行最终精排,得分最高的则为模型预测的企业UBO。最后通过蚂蚁体系内实名认证得到的用户姓名、地址、证件号码、证件有效期对企业UBO四要素进行补充。央行要求对模型推理结果给出可解释才能通过验收,因此最后一步是对推理结果的可解释,本方案中采用路径打分的方式为支持预测结果的每个可达路径计算出贡献打分,它先基于KGDSL关联分析找到每个pair对的所有可达路径,然后基于序列模型KPRN计算路径的打分,最后把得分最高的top N条路径输出并基于KGDSL形式化描述和输出。
图谱因其天然可解释友好的实体之间语义关联,可方便查询预测结果的N跳级连,最终通过图谱表征 + 路径解释的组合方案在UBO场景也取得了很好的的效果,无论结果预测准确率还是可解释路径覆盖,都有显著的提升,并最终顺利通过了央行验收。此外从本案例中可以窥见基于知识图谱的可解释正逐渐成为AI模型可解释的重要方向之一。
知识图谱总体架构
蚂蚁知识图谱在建设过程中先后经历了三次较大的架构重构,基本上也应对了图谱规模的三次重大的规模跃迁:第一阶段是在建设初期以提供知识服务为主要目标,基于图数据库+搜索引擎提供服务能力,支撑规模<10亿。第二阶段应用规模扩大以提供知识服务及离线表征推理为主要目标,增加离线的回流及子图样本计算,支撑规模约100亿。第三阶段以满足多样化图谱业务自助接入及支撑多下游推理、服务任务为主要目标,构建了知识仓储架构,线性扩展支撑规模超10000亿量级。
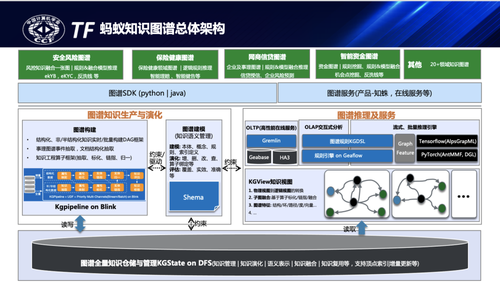
第三阶段的架构重构基本形成了当前比较稳定的知识图谱系统引擎,结合业务持续迭代优化,如上图所示,它在能力设计上主要包括知识建模、图谱构建、知识仓储、推及服务、开放SDK及产品平台等六部分,下面是就其中部分能力展开的介绍。
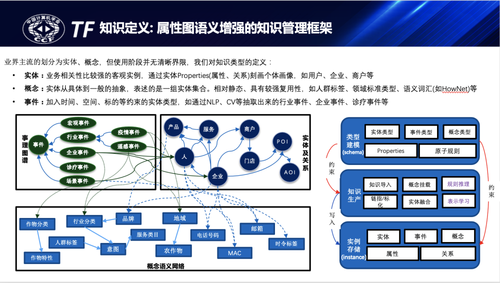
首先是图谱知识建模。尽管OWL/RDF有较为完备的知识表示体系,但因其过于复杂被诟病较多,工业落地中大多还是基于属性图知识建模,以减少业务和数据人员的理解成本,也能够促进业务价值的快速落地。属性图、RDF图都有坚实的拥趸群体,社区的相关讨论也比较多。属性图是强结构弱语义的,它克服了表外键关联带来的效率和性能问题,应用门槛相对较低,RDF图是强语义弱结构的,它因对语义完备性的要求而大大提高了从业者的应用门槛。若实现他们之间的优势互补,取长补短,则将极大的提升知识图谱的应用效率,业界也有较多RDF图和属性图兼容的做法。
蚂蚁知识图谱采用的是在属性图的基础上不断丰富知识语义表达,在业务易用性和语义完备性上不断探索和取舍,结合金融知识图谱的特点,把核心主体分成三类并定义他们之间相对明确的能力边界,如图所示,包括实体、概念、事件三类:
•实体:业务相关性比较强的客观实例,通过实体Predicates(属性、关系)刻画个体画像,实体往往指的是业务决策的具体对象,如用户、企业、商户、产品等。
•概念:它表述的是一组实体的抽象集合,指的是实体从具体到一般的抽象,它相对静态、具有较强复用性,如人群标签、领域标准类型、语义词汇(如HowNet)等。
•事件:加入时间、空间、标的等约束的多元关联的特殊实体类型,如通过NLP或多模态算法结构化抽取出来的行业事件、企业事件、诊疗事件等。
概念可以方便沉淀通用常识知识,相对静态且可以更大范围的复用;事件则方便沉淀不同颗粒度的风险事件,如宏观政策、中观行业、微观企业甚至交易事件等,用以实时风险洞察和历史事件回测等。实体、事件通过属性的挂载实现与概念之间的链接,某种意义上概念也是文本型属性的取值约束。除了主体类型定义外,还有谓词的语义定义,也充分参考、引用了OWL谓词体系如subClassOf, equivalentClass, inverseOf等,并做了适度扩展如subCategoryOf, subPredicateOf, normalizeProperty等以提升知识管理的效率,通过对谓词、概念也扩展定义了基于标签、关系的可解释、可复用的规则推理基础能力。
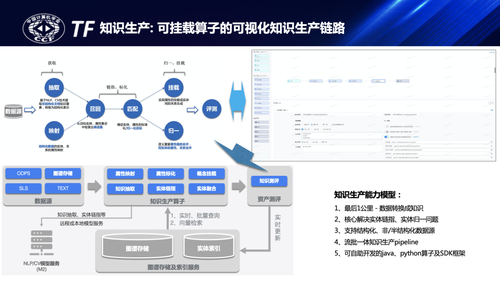
结合图谱平台对知识标准化、消歧去重、语义关联等的要求和定义,定义了知识生产框架,上图是图谱的知识生产框架,知识生产的过程本质上就是按照图谱的schema规范约束实现业务数据的图谱化知识化,如何高效实现这个转换又能降低业务的理解和应用成本是在知识生产中需要重点解决的问题。经过多年的打磨,蚂蚁从算子框架抽象、算法组件联动、多数据源统一等角度出发抽象了整体的知识生产pipeline,并提供了python/java sdk及可视化可拖拽DAG的方式支持不同业务&算法的迭代:
•算子框架抽象:主要围绕定义标准化、消歧去重、关系生成等定义了基础的文档要素抽取、实体链指/属性标化、实体融合、可信测评等基础算子interface及相关组件,方便算法迭代开发又方便平台将其自动组装成pipeline。
•算法组件联动:知识生产过程中会用到的多种模态算法及系统能力,既要支持NLP/多模态算法联动以实现不同的半/非结构化数据理解和抽取,如事件抽取、文档要素理解等,又要实现与基础文本匹配、向量召回的搜索引擎联动,复杂情况下还要支持多模态与图谱联动的知识约束的抽取、推理预测等,这些都沉淀在了基础组件中。
•多数据源统一:主要结合两个视角做整体抽象,一是多外部数据源类型,结构化、非/半结构化数据的图谱构建与转换,先映射到结构化要素上,二是基于已构建好的领域图谱实现跨图谱融合与连接。
知识生产框架在蚂蚁各领域图谱迭代中有比较多的应用,算子及框架能力也随着业务应用的深入不断打磨,目前知识生产链路日更新能力也达千亿规模。
结合前图的总体架构,知识图谱还有一个非常重要的基础能力,知识仓储。知识仓储解决超大规模线性扩展的知识存储及多下游任务差异化分发、加载效率问题,最大化提升资源利用率,除此外还实现了语义标准化的仓储模型,语义特性layout、跨业务零拷贝知识融合、语义图/属性图的兼容与互转等。
图谱的推理及服务任务是多种多样的,有高性能tugraph/搜索引擎在线服务、也有离线/流式的规则推理/表示学习等,本次介绍下图谱推理框架,它实质上是一套方便业务、算法迭代的知识科学工具集library,并支持算法创新与迭代,它的核心出发点是如何支持算法及业务人员高效地进行图谱数据读取、提取关键子图结构、子图特征等。
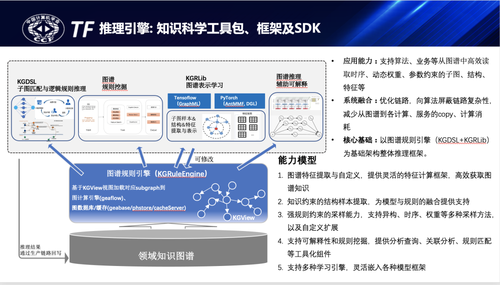
在实际业务应用中,蚂蚁主要提供了两种核心基础能力,一个是图谱规则推理KGDSL,另一个是图谱表示学习框架KGRLib。首先介绍图谱规则推理,前面介绍过在金融领域图谱构建过程中如何支持业务专家经验的高效沉淀是一个核心基础问题,在完成专家规则沉淀后又如何支持专家经验的前向或后向推理是KGDSL要解决的问题,蚂蚁知识图谱的规则推理主要从如下几个角度进行了抽象:
•子图结构匹配: 金融风险模式不是简单的路径、关系表达,结合前述安全风险图谱的介绍,它更多是复杂的子图结构模式,围绕子图匹配的subgraph pattern matching关键基础能力,为方便业务应用采用GraphStructure、Rule、Acton三段式表达抽象了KGDSL。每个业务小二都会结合专家经验配置大量的规则模式,比如花呗套现模式、中间人洗钱模式、击鼓传花模式等等。
•浓度聚合计算:相对于OWL单通路的基于事实facts的推理表达,在金融图谱风险判定的应用中即便满足了结构约束也未必能标注为一个风险行为,通常需要在一定时间窗口、地域约束下达到一定聚合上限后才能被识别为具体的风险行为,为此在满足结构约束后还需要支持浓度的聚合计算。
•原子规则沉淀:原子规则沉淀类似公理性规则的沉淀,具有一定的跨业务、跨场景的复用价值,这部分也在探索和应用落地过程中,通过定义概念规则及谓词规则语义实现原子规则沉淀。
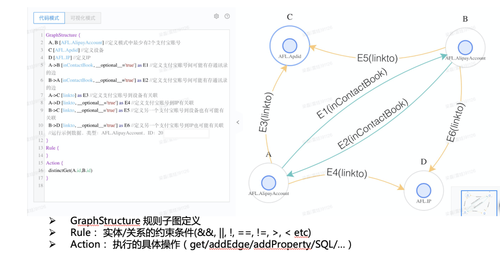
上图给出了KGDSL的简单示意,用户可以通过可视化或KDSL形式化的方式来定义graph pattern及其约束条件,并将结果输出或进一步的聚合计算。
图谱表示学习框架解决的核心问题是图谱特征、子图提取问题,图,并适配到主流的深度学习框架如tensforflow/pytorch上,并转换成对应图学习算法需要的tensor结构。
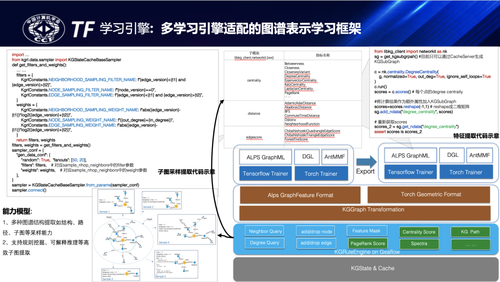
蚂蚁知识图谱表示学习推理主要围绕四个方面展开:
•异质图表示学习:结合GCN类图学习基础能力和图谱语义表示,提出了基于Encoder-Decoder的自监督知识表示学习框架KARI,它结合图谱异质且丰富的实体类型、实体属性、概念、关系等,融合图谱语义信息、子图特征、事件时空多元(hypergraph)关联构建的图谱表征学习框架。相关能力的应用也比较广泛,在诸如搜索推荐、风险防控等多场景应用中都取得了不错效果。
•规则&模型融合:结合前面的介绍,金融场景有较多的专家规则沉淀,实现专家规则与模型的有效融合能较好的提升规则泛化,也能更好的引导模型高效地学习,复用KGDSL子图结构采样,充分发挥深度学习的学习能力和专家规则少样本标注的优势,既可以减少所需要的样本量 (如风控标签稀疏场景、推荐冷启动等),也能让模型的学习更符合专家预期。相关能力也在用户可证、商户套利等场景取得了不错效果。
•图谱规则挖掘:更高效的发现新的规则能较大程度提升业务小二的作业效率,同时规则挖掘也是图谱推理可解释的关键依赖, 业界也有ILP、AMIE、PRA等规则挖掘方案,前面也介绍了一个安全场景可解释的案例。蚂蚁知识图谱结合图谱特点沉淀了基于事实关系、属性语义关联的规则挖掘算法,通过不断的性能优化提升全路径空间搜索的规模,已实现千亿级超过四跳的全路径挖掘,相关能力在商户同店挖掘、欺诈团伙等场景中有不错的效果。
除以上三类外,蚂蚁知识图谱也在因果推断上不断探索和尝试,图谱算法也搭建了结构因果模型和潜在结果框架两大因果推断体系,通过结构学习支持数据集归因、单样本归因等能力用于推荐结果可解释、异动分析等,后者通过纠偏、混淆因子发现等进行更准确推荐营销效果评估、圈人等。
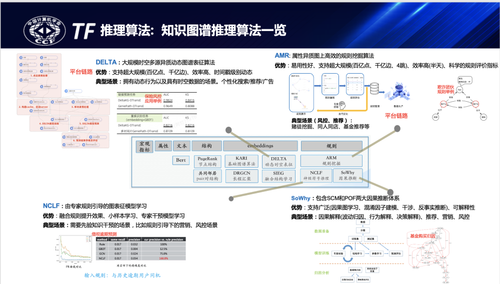
发展与展望
最后在知识图谱的发展及展望中,梁磊谈到了知识图谱近些年的发展阶段:通用知识图谱、领域知识图谱、企业级知识图谱,并对三个阶段进行了详细说明。
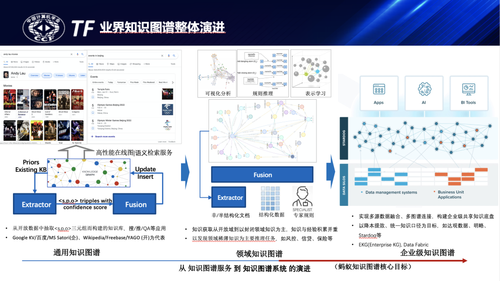
知识图谱是一个又古老又崭新的领域,知识图谱的理论基石包括语义网、符号逻辑、专家系统等已经有很多年的发展,有非常完备的理论体系和基础工具支撑,但知识图谱作为新一代数据/知识管理工具的价值也在被不断定义和发现,随着图计算、图存储、深度学习技术所依赖的算力和算法能力不断提升,知识图谱又爆发出巨大的发展潜力,相关技术的创新和发展也日新月异,期待更多的行业同仁一起推动知识图谱技术的发展和应用的落地。
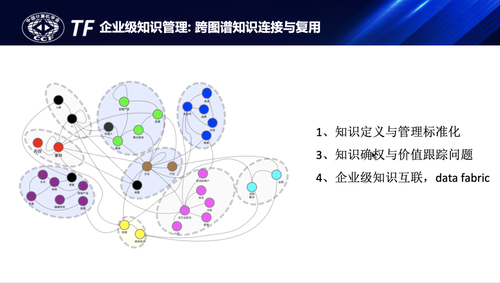
在进一步的发展上,他提到了如何高效的实现跨业务的知识连接与共享是需要持续研究和优化的课题,为实现这一目标还需要解决这几个关键子问题:知识定义的语义标准化、知识的确权与价值跟踪、企业级知识高效互联。
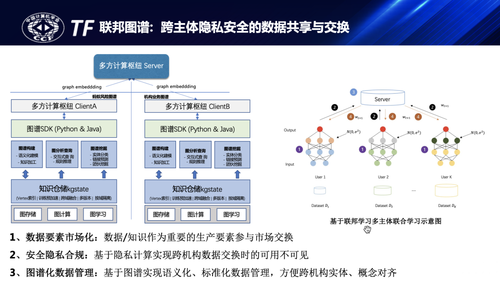
放在更大的视角上,知识、数据作为重要生产要素被市场化并参与价值交换,隐私计算可以有效解决跨机构隐私合规数据交换及计算问题,但没解决知识建模和知识管理问题。知识图谱与隐私计算的结合,可以实现参与主体的知识定义标准化,在保留语义关联的同时结合隐私计算实现跨机构的知识共享。联邦图谱作为跨机构知识融合的解决方案也越来越受到关注,近期涌现了大量的隐私图学习相关论文也都是在这个方向上的探索,下图示意了基于联邦学习的跨机构图谱联邦学习的过程,隐私图学习、图谱融合等,随着技术的成熟未来也会发挥更大的价值。
知识图谱给业务提供了一种新的知识管理范式,相对于图计算、图数据库它具有更强的业务属性,下一步的发展还需要实现图谱能力与行业通用解决方案的融合,如安全风控、保险理赔、可解释决策、事理图谱等,通过沉淀行业解决方案和组件进一步降低业务落地成本,降低小二的理解成本,实现与业务系统的高效衔接。
知识图谱相关基础技术和应用场景也在快速发展,整体上处于上升阶段,也有很多不成熟和需要持续探索的地方,本文总结了蚂蚁在工业实践中遇到的问题、思考和尝试,知识图谱尤其在金融场景具有非常广阔的应用空间,也期待与业界同仁有更多的交流和合作,一起探索推进技术的进步和行业的应用,推进金融知识图谱的标准化和解决方案的建设。
关于CCF TF知识图谱SIG:



主席:王昊奋
同济大学特聘研究员
语言理解与认知推理是人类区别于其他动物的能力,同时,不断地凝练、传承知识,是推动人类进步的重要基础。通过不同知识的关联性形成一个网状的知识结构。形成知识图谱的过程本质是在建立与完善认知。知识图谱将会让机器具备理解、推理和解释的能力,从而使人工智能从感知阶段升级到认知,并引领智能时代的来临。来这里,让我们一起实现“认知智能”!
本场活动视频CCF会员可免费回看:

会员权益
会员免费参加CCF TF全年47场活动,为自己的技术成长做一次好投资,以高性价比获取专业知识的绝佳路径!

长按识别或扫码入会
联系方式
邮箱:tf@ccf.org.cn
电话:0512-8391 2127
手机:18912616058
合作媒体

CCF推荐
【精品文章】




所有评论仅代表网友意见